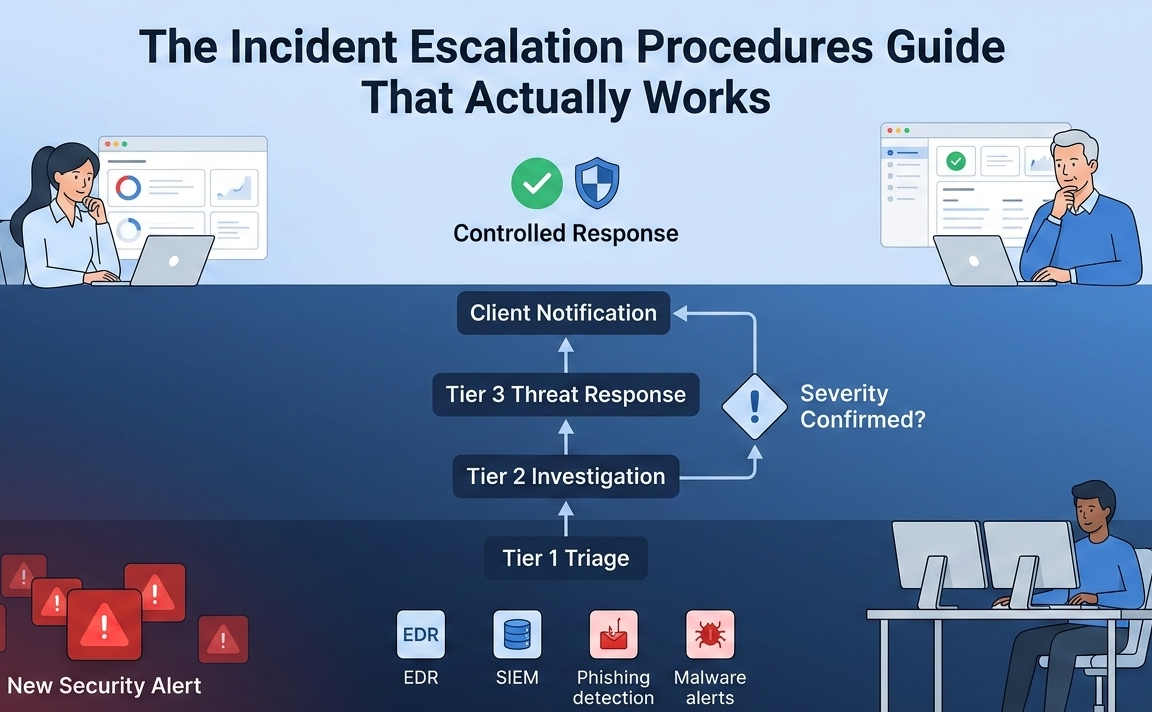
Your incident escalation procedures guide are broken if your team is playing notification ping-pong while a critical system burns. The fix isn’t more software, it’s a clear, agreed-upon map of who needs to know what, and when.
A robust escalation plan turns chaos into a coordinated response, protecting your operations and your customer experience. Keep reading to transform your incident management from a source of stress into a reliable system.
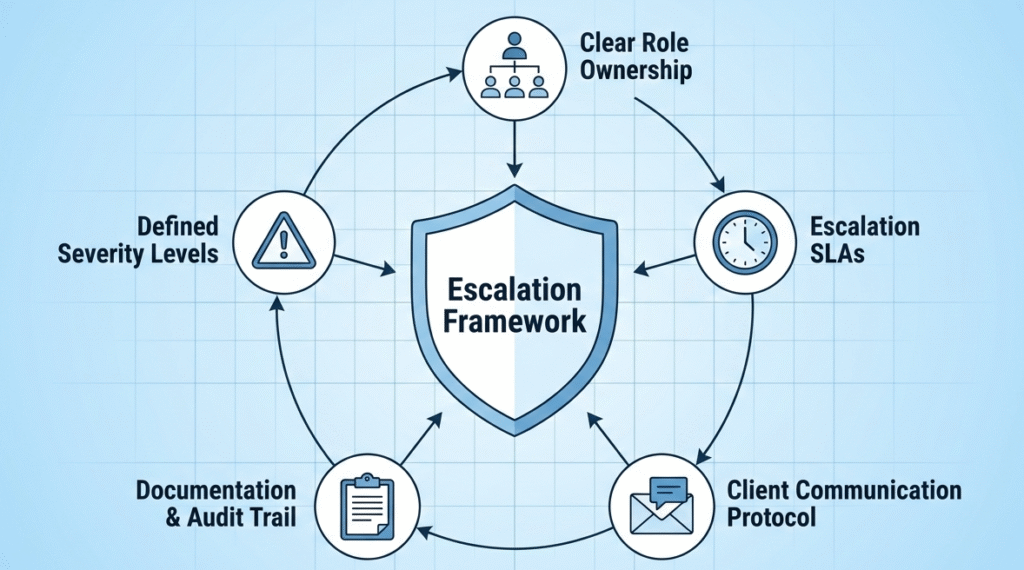
The Three Pillars of Effective Escalation
- Define Explicit Triggers: Move beyond gut feelings to time-based and severity-based rules that automate the handoff.
- Map Communication Pathways: Pre-wire exactly how to notify stakeholders, from tech teams to executives, for each severity level.
- Practice and Refine Relentlessly: Your plan is a hypothesis until tested with tabletop drills and real post-incident reviews.
The Core of a Reliable MSSP Incident Escalation Process
We’ve seen the alternative, the frantic Slack searches, the missed calls, the valuable minutes lost. A structured mssp incident escalation process is your antidote. It’s the predefined highway that an incident travels down, ensuring it doesn’t get stuck in a ditch. This isn’t about bureaucracy.
“For SOC teams, the biggest risk is unclear escalation and ownership. When incident management roles and responsibilities are not defined, teams improvise under stress. That improvisation often becomes the most expensive part of the incident.” – NetWitness
- It creates a reliable, repeatable system.
- It aligns internal teams with client expectations from the first alert.
- The goal is simple: the right person gets the right context at the right time.
Defining Incident Escalation Triggers with Precision
Credits: Mike Chapple
Vague feelings don’t scale. You need concrete, defining incident escalation triggers that remove ambiguity. Think in terms of clocks and thresholds.
- Time-based escalation: No acknowledgment within 15 minutes for a High-severity ticket.
- Scope-based escalation: Number of affected users exceeds a predefined threshold.
- Risk-based escalation: A critical security measure fails or a compliance violation is suspected.
Crafting Your Security Incident Communication Plan
When the sirens blare, nobody should be wondering how to shout. Your security incident communication plan dictates the channels and cadence. For a low-severity alert? Maybe a Slack update in a dedicated channel.
For a critical event disrupting customer experience? That’s a phone bridge, immediate SMS blasts, and templated executive briefs. The plan assigns a comms lead, a single voice to craft external messages, so the technical team can focus on containment. This separates internal chatter from client-facing clarity.
Notifying Stakeholders During an Incident Without the Panic

Notifying stakeholders during incident scenarios is a delicate art. The key is a pre-defined hierarchy.
- Primary responder handles initial triage.
- Secondary contacts (e.g., department management) are notified if thresholds are met.
- Tertiary/Executive teams are engaged for critical events.
Each notification should follow a template: impact, actions, next update time.
The Nuts and Bolts of Escalating Critical Security Events
Escalating critical security events requires a “stop the line” mentality. For a suspected ransomware deployment or massive data breach, the trigger is immediate.
- The incident manager is engaged; a war room is opened.
- Executive response teams are notified within minutes.
- Documentation of the incident timeline starts instantly to marshal all resources.
A Practical SOC Escalation Matrix Example
Let’s make it tangible. A soc escalation matrix example turns policy into action.
| Severity | Impact | Time to Escalate | Primary | Secondary | Exec/Client Notify |
| Low | Single user, minor issue | 4 hours | L1 Analyst | L2 Engineer | No |
| Medium | Group of users, no outage | 1 hour | L1/L2 Team | Incident Manager | Optional |
| High | Service disruption, data risk | 15 minutes | L2/On-call | Incident Commander | Yes, per SLA |
| Critical | Business-wide outage, breach | Immediate | Incident Commander | CISO/Client Lead | Immediate, ongoing |
Demystifying Incident Severity Escalation Levels
Those incident severity escalation levels, Low, Medium, High, Critical, are your common language. Their definitions must be co-owned with your clients to avoid disputes. Is a failed remote access tool for one user a “Medium” or a “Low”? Decide upfront.
“Your incident escalation plan serves as the backbone of your incident management system. It ensures that incidents don’t sit unattended or bounce aimlessly among teams without resolution. In essence, this plan is a conductor orchestrating various sections of the symphony that makes up your incident management system.” – incident.io
Each level must be tied to a target Time to Acknowledge and Time to Resolve within your Service Level Agreement. This shared vocabulary ensures that when you call something “Critical,” everyone, from the tech professional to the legal team, understands the gravity and responds accordingly.
Managing Incident Response Team Communication Effectively
Managing incident response team communication is about creating a single source of truth. All actions, hypotheses, and updates go into the central incident record, be it a Zendesk ticket or a Jira ticket. Use a dedicated Slack channel or Teams room for real-time chatter, but mandate that key decisions are documented in the main record.
This prevents the swarming approach from becoming a confusing mess. A designated shift supervisor can help direct traffic, ensuring the technical teams aren’t bottlenecked by communication overhead.
The Essential Post Incident Escalation Review
The incident is resolved, but your work isn’t. The post incident escalation review is a non-negotiable learning tool.
- Did the escalation thresholds work?
- Were the right people notified on time?
- Was the communication pathway clear?
This root cause analysis of the process outputs an updated playbook and refined matrix.
Testing Incident Escalation Procedures Before You Need Them

Your plan is a fantasy until you stress-test it. Testing incident escalation procedures through quarterly tabletop exercises builds muscle memory.
- Simulate a critical security event.
- Trigger your on-call notifications and practice stakeholder updates.
- Expose gaps in rotation schedules or override rules in a safe environment.
FAQ
What should an effective incident escalation process include?
An effective incident escalation process clearly defines severity levels, escalation thresholds, and response time standards. It connects your incident management process with a documented escalation policy and incident response plan.
You also need clear communication pathways, decision authority matrix, and an up-to-date escalation matrix. Strong governance structure, audit trails, and real-time notifications help reduce escalation delays and protect customer experience during IT incidents.
How do severity levels improve escalation management?
Clear severity levels remove guesswork during incident escalation. When tied to a Service Level Agreement and Time to Acknowledge targets, they guide Severity-Based Escalation and Time-based escalation decisions.
An incident priority matrix ensures the right team member, on-call responder, or executive teams are engaged fast. This structure strengthens escalation management, protects customer satisfaction, and keeps the response process aligned with real business impact.
What causes escalation delays in incident management?
Escalation delays often come from unclear escalation thresholds, manual processes, and poor on-call schedules. If rotation schedules, staffing levels, or shift schedules are misaligned, the on-call engineer may miss critical on-call notifications.
Lack of real-time notifications, override rules, or defined Internal Escalation Protocol also creates confusion. Without clear incident response policies, escalation management becomes reactive instead of controlled and predictable.
How can automated escalation improve response time?
Automated escalation reduces reliance on manual processes and speeds up response time standards. It triggers functional escalation or hierarchical escalation based on predefined rules in your escalation system. Real-time notifications alert the right on-call responder according to the SRE On-Call Rotation.
Automated escalation also logs actions in the incident record, improving audit trails and supporting learning and improving through better Escalation Metrics.
Your Path to Escalation Confidence
Building a dependable incident escalation process isn’t about adding paperwork, it’s about creating clarity when things go wrong. Define clear triggers, set simple communication paths, and practice regularly so your team responds quickly and confidently.
Ready to improve your escalation process? Join our MSSP consulting program. We provide vendor-neutral advice, stack optimization, and practical guidance backed by 15+ years of experience and 48K+ completed projects to help you streamline operations and improve service quality.
References
- https://www.netwitness.com/blog/incident-response-process/
- https://incident.io/blog/effective-incident-escalations
Related Articles
- https://msspsecurity.com/mssp-incident-escalation-process/
- https://msspsecurity.com/defining-incident-escalation-triggers/
- https://msspsecurity.com/security-incident-communication-plan/
- https://msspsecurity.com/notifying-stakeholders-during-incident/
- https://msspsecurity.com/escalating-critical-security-events/
- https://msspsecurity.com/soc-escalation-matrix-example/
- https://msspsecurity.com/incident-severity-escalation-levels/
- https://msspsecurity.com/managing-incident-response-team-communication/
- https://msspsecurity.com/post-incident-escalation-review/
- https://msspsecurity.com/testing-incident-escalation-procedures/