
When an alert flashes red, you need to know who to call and how fast. That’s what incident severity escalation levels are for. They’re the playbook that tells your team whether to send a Slack message or wake the CEO at 3 AM.
Without them, you’re just guessing, and during a ransomware attack or a data breach, guesses cost millions. I’ve seen SOCs drown in noise because their escalation path was a mess of sticky notes and forgotten runbooks. This framework brings order. It turns chaos into a coordinated response. Keep reading to build a matrix that actually works under pressure.
Important Points to Remember
Before building or improving your escalation framework, it helps to understand the main ideas behind incident severity escalation levels.
- Clear severity levels (P1-P4) dictate your entire response, from initial triage speed to executive involvement, based on concrete business impact.
- A tiered SOC structure divides labor efficiently, ensuring the right expertise engages at the right time to contain threats faster.
- Dynamic, context-aware triggers powered by modern tools move beyond static rules, enabling automatic escalation for critical assets like a CFO’s compromised laptop.
What is a SOC Escalation Matrix and Why Is It Necessary?
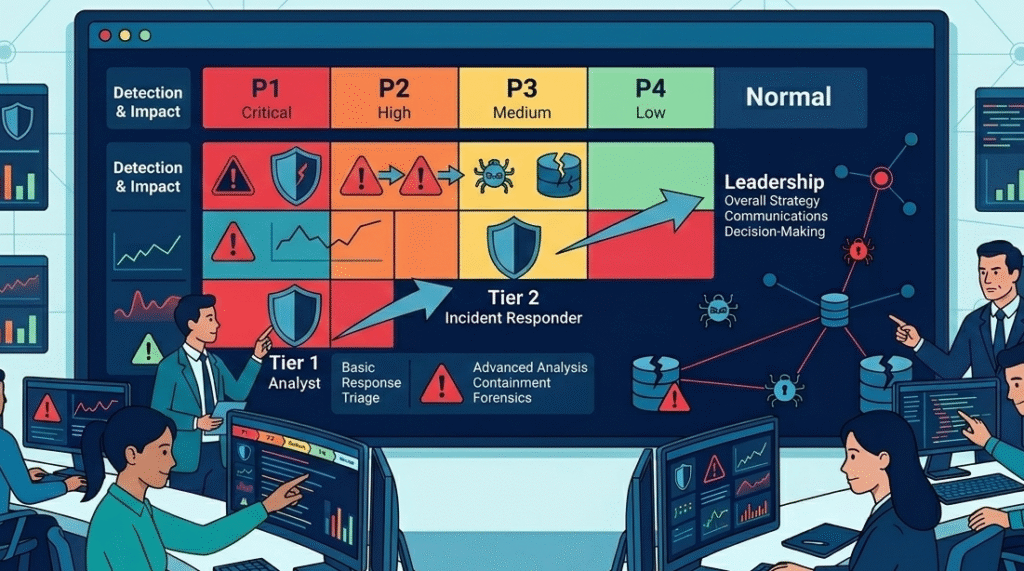
Walk into most SOCs and you’ll see the same thing: dashboards everywhere and a constant stream of SIEM alerts. The real challenge isn’t detection, it’s deciding what actually matters. A SOC escalation matrix gives teams a clear structure for prioritizing incidents, triaging alerts, and handing them off to the right people based on severity, impact, and timing.
In our consulting work with MSSPs, we’ve seen how messy escalation paths slow down response. Sometimes it’s a spreadsheet no one updates, sometimes a runbook buried in a shared drive. A proper matrix replaces guesswork with a repeatable process that holds up under pressure.
It helps teams by:
- Standardizing incident escalation procedures through severity-based tiers; Assigning clear ownership for every escalation level.
- Assigning clear ownership for every escalation level
- Supporting SLA tracking and faster MTTR
- Preventing critical alerts from getting lost during alert storms
How Do Incident Severity Levels (P1–P4) Determine Response?
Credits: Plow Networks
Incident severity escalation levels are the language a SOC uses to decide how fast to act and who must get involved. They categorize threats from critical to informational while linking them to real business impact.
A high CVSS score alone doesn’t tell the whole story. During several MSSP consulting projects, we’ve seen the same vulnerability ranked very differently depending on where it appeared. A flaw on a public-facing server is far more urgent than the same issue on a lab machine.
A P1 incident means operations are already disrupted. Think ransomware spreading, a domain controller compromise, or confirmed data exfiltration. That type of event triggers immediate response and leadership involvement. At the other end, a P4 alert might be routine scanning activity that analysts can review during normal hours.
| Level | Impact Type | Initial Response SLA | Resolution Target | Escalation Path |
| P1 – Critical | Active breach, ransomware, widespread outage | <15 Minutes | <4 Hours | T1 → T2 → CISO/Exec → External IR |
| P2 – High | Confirmed malware on critical asset, suspicious privileged login | <30 Minutes | <24 Hours | T1 → T2 → SOC Manager |
| P3 – Medium | Policy violation, anomalous behavior, suspicious IOC | <1 Hour | <48 Hours | T1 → T2 |
| P4 – Low | Informational alerts, routine scans, false positives | <4 Hours | <5 Days | T1 only |
The key is that these levels dictate everything: speed, seniority of responder, and communication cadence. A P1 wakes people up. A P4 waits for the morning stand-up.
Who is Responsible at Each Level of the SOC Hierarchy?
Responsibility in a SOC follows the incident severity escalation levels, but the work itself is split across analyst tiers. This model exists for a reason. Without it, teams burn out quickly while critical threats still slip through.
In many SOC environments we review during consulting engagements, Tier 1 analysts handle the bulk of alerts. Their role is triage: validating events, filtering obvious noise, and running basic response playbooks. Most alerts stop here. Only confirmed or suspicious incidents move forward.
Tier 2 analysts focus on deeper investigations. They examine logs, determine root causes, and begin containment actions such as isolating systems or revoking credentials. When threats appear more advanced, Tier 3 specialists step in for threat hunting, malware analysis, and persistent attacker investigations.
Leadership enters the picture when business risk rises. SOC managers coordinate resources while CISOs step in during severe incidents to manage legal exposure, communications, and executive decisions.
What Triggers a Functional vs. Hierarchical Escalation?

Not every escalation happens for the same reason. Sometimes a team needs technical expertise, while other situations require management decisions.
“Good severity definitions remove ambiguity, speed up triage, and set clear expectations for response times and escalation paths.” – OneUptime
Functional escalation happens when a technical issue becomes too complex for the current analyst. For example, a Tier 2 analyst may escalate a difficult network intrusion case to a threat hunter or forensic expert.
Hierarchical escalation moves up the management chain. This happens when an incident affects business operations or requires leadership approval.
Common escalation triggers include:
- Automatic triggers: ransomware activity, domain admin compromise, confirmed data exfiltration
- Time triggers: incidents that exceed their resolution SLA
- Context triggers: alerts involving executives, sensitive databases, or critical systems
These triggers ensure the process for escalating critical security events is handled quickly, preventing delays when risk is at its highest.
How Does Modern Automation Transform the Escalation Process?
Many SOCs used to rely on static rules and manual triage. In practice, this approach struggles with high alert volumes.
Today, automation helps process alerts faster. Systems can evaluate asset importance, user roles, and threat intelligence data before analysts review the alerts. This provides better context for incident severity escalation levels.
Automation can also filter large numbers of alerts and prioritize the most critical ones. In some environments, it handles most Tier 1 triage tasks.
For serious threats, automated actions may isolate infected devices or revoke access immediately. This reduces response time and allows analysts to focus on deeper investigations.
Building a Response Framework That Doesn’t Crumble
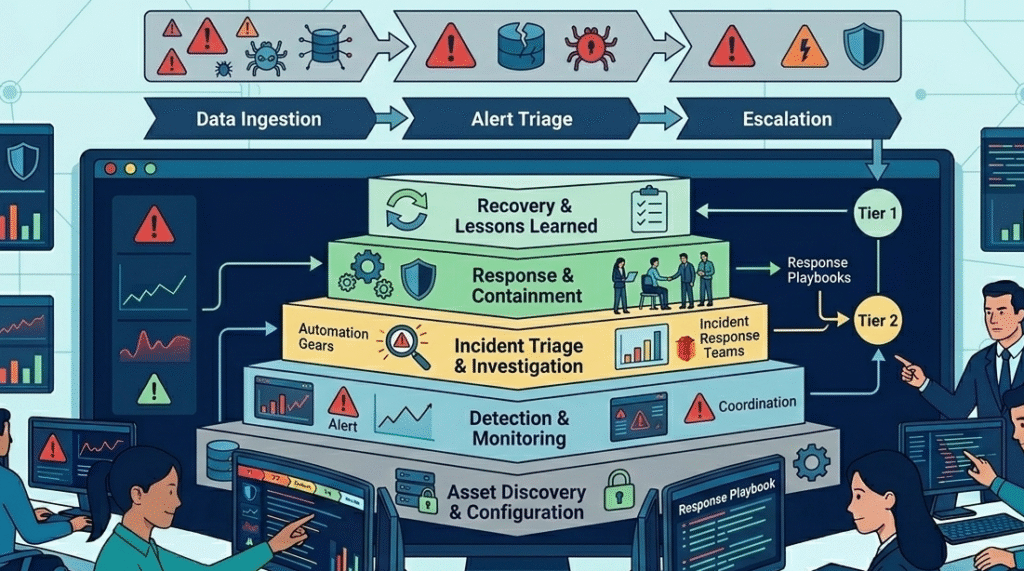
An escalation framework only works if it becomes part of daily SOC operations. We often see a soc escalation matrix example stored in documents that analysts rarely check during incidents, rather than being built into the live workflow.
“When the severity levels defined in the matrix correspond with the timelines and escalation paths established in the SLA, teams can respond to incidents with consistency and transparency.” – InvGat
Instead, escalation rules should be integrated into the tools teams already use. Ticketing systems and response platforms can automatically assign incidents, track SLAs, and notify the right people.
Strong frameworks usually include:
- Tool integration: escalation rules inside response workflows
- Regular testing: tabletop exercises to practice incident scenarios
- Frequent updates: review contacts and triggers every few months
- Clear outcomes: focus on faster response and lower MTTR
A practical system evolves over time and adapts to new threats and operational changes.
FAQ
How do organizations decide the correct incident severity levels?
Organizations usually determine incident severity levels by evaluating business impact, urgency rating, and outage classification. Teams assess asset criticality, confidentiality impact, and user affected percentage to rank incidents correctly.
A priority matrix helps compare factors like revenue loss, compliance violation risk, and operational disruption. This structured impact assessment ensures incidents receive proper incident prioritization instead of relying only on technical alert severity.
When should an incident escalate from SEV3 medium to SEV2 high?
An incident may escalate from SEV3 medium to SEV2 high when the business impact grows beyond the original scope. For example, a policy violation or degraded service might appear minor at first.
If the impact scope expands, or the incident duration threshold approaches an SLA breach, teams may reclassify severity levels to accelerate response time and resource allocation.
What role does asset criticality play in incident prioritization?
Asset criticality strongly influences how incident severity levels are assigned. Security teams consider whether the alert affects critical infrastructure, sensitive customer data PII, or core operational systems.
If a domain controller compromise or CFO endpoint malware appears, the escalation matrix often pushes the event toward P1 priority or SEV1 critical, even when the original alert looked moderate.
How can SOC teams reduce alert fatigue during incident triage?
Alert fatigue often occurs when analysts handle too many SIEM alerts without proper filtering. SOC triage processes help tier 1 analysts separate log noise and false positive triage from real threats.
By using threat hunting triggers, risk scoring, and clear escalation paths, security teams reduce unnecessary investigations and allow tier 2 investigation or tier 3 response to focus on serious incidents.
Final Thoughts on Severity Escalation
Incident severity escalation levels help security teams respond with clarity instead of panic. A structured escalation matrix ensures the right people see the right incident at the right time, preventing critical threats from being buried in alert noise.
Define severity levels based on real business impact, connect them to SOC tiers, and automate triggers for high-risk events. For expert help optimizing tools and escalation workflows, explore consulting from MSSP Security.
References
- https://oneuptime.com/blog/post/2026-01-30-incident-severity-definitions/view
- https://blog.invgate.com/incident-severity-levels