
When the alert hits, a systematic investigation kicks in. That’s what stops chaos. It’s a structured process, turning noise into a clear path forward. The team moves from triage to final report, shifting from “something’s wrong” to knowing exactly what happened and how to fix it.
This is the daily work: linking SIEM alerts to EDR data, following digital traces until the story makes sense. Build a process that works under real pressure. Keep reading to sharpen your incident investigation analysis steps without chaos.
Investigation Insights at a Glance
- A defined process turns reactive panic into a controlled, repeatable investigation.
- Correlating events across tools (SIEM, EDR) is essential for accurate scoping and root cause analysis.
- Meticulous documentation isn’t just for compliance; it’s the blueprint for preventing recurrence.
The Security Incident Investigation Process, Demystified
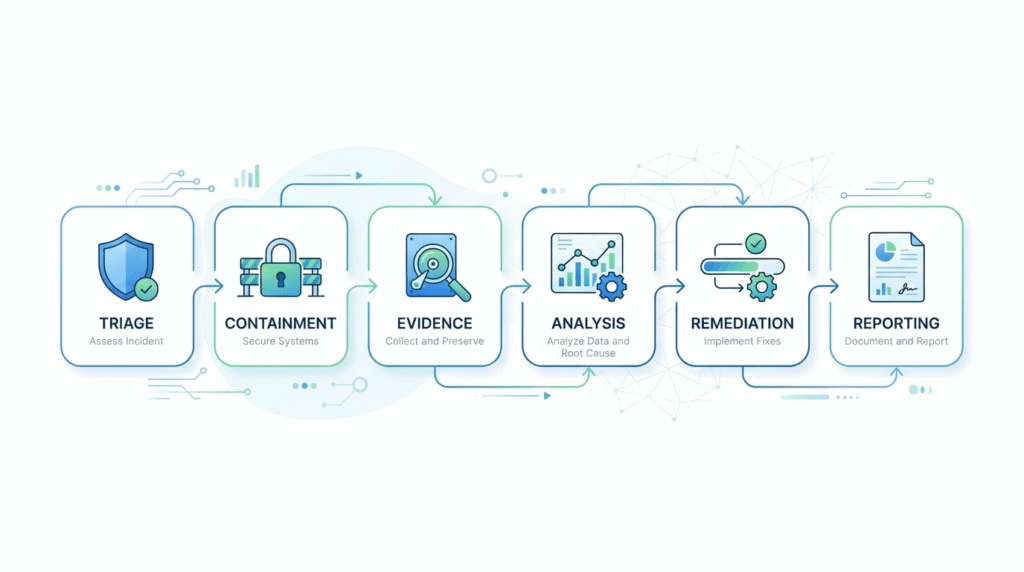
That phrase security incident investigation process sounds like something from a consultant’s slide deck. In reality, it’s just the checklist you run through when alarms go off. It’s the framework that stops your team from spiraling into chaos.
“Analyze the data. Use root cause analysis tools to identify the underlying causes of the incident. This is where you ask, ‘Why?’ multiple times. Develop corrective actions based on your findings.” – Perpusnas
We’ve watched investigations fail because teams dove into forensic details before asking the most basic questions: What actually happened? How bad is it? A solid process works like a funnel. You start wide to validate the alert and assess the scope, then you narrow your focus down to the specific root cause.
This method ensures evidence is gathered properly and every action isolating a server, talking to an employee, gets documented. For an MSSP managing multiple clients, this structure is everything. It’s how you keep the chain of custody intact and maintain clarity across totally different IT environments.
SOC Analyst Alert Investigation Steps: Your First 15 Minutes

The opening of an investigation sets everything up. Following specific soc analyst alert investigation steps ensures that an analyst focuses on fast, accurate sorting rather than deep forensics.
It starts with that alert in your SIEM or EDR. You see the timestamp, the IP, the username. The immediate questions are: does this look like a known attack? Is this normal behavior for this system or person? Jumping from the SIEM alert over to the actual EDR agent data gives you the real story, was a weird process started?
Did registry keys get changed? This early dot-connecting is a core skill we see separating junior and senior analysts. In our audits of MSSP teams, we stress this phase constantly. Those initial minutes frequently dictate the final toll of a breach.
A Quick Triage Checklist
- Verify the alert is genuine, not a drill.
- Assess the asset’s importance and what data is on it.
- Review events from 15 minutes before and after.
- Run a fast check for known IOCs.
- Decide if you need to isolate the system now.
How to Analyze a Security Incident: Beyond the Surface Alert
Once an incident is confirmed, the real work begins. The steps to analyze a security incident move from “what” to “how” and “why.” This is where you build a timeline. You start with the point of detection and work backwards, using your SIEM to query for related events.
You look for the initial access vector, was it a phishing email, an exploited vulnerability, a misconfigured cloud bucket? Then, you map the movement. Using EDR tools, you chart process creation chains, network connections, and file modifications. You’re looking for tactics, techniques, and procedures (TTPs) that map to frameworks like MITRE ATT&CK.
The analysis phase is iterative; each new piece of evidence prompts new queries. It requires patience and a healthy skepticism, always questioning assumptions. The root cause is rarely the first obvious answer; it’s often found several layers deeper, in a missed patch or a lack of user training.
Digital Evidence Collection and Analysis: Building a Defensible Case
Digital evidence collection and analysis is the backbone of any serious investigation. From what we’ve seen supporting MSSPs, the biggest mistakes happen during evidence handling, not detection.
It’s never just about pulling logs; it’s about preserving integrity for potential legal scrutiny. That means maintaining clear chain of custody records, who collected the data, when, and under what conditions.
In practice, our teams insist on hashing (SHA-256) before analysis and working from verified copies in isolated labs. Analysts then reconstruct timelines, inspect memory, and review PCAPs. Proper correlation turns scattered alerts into defensible, audit-ready findings.
| Evidence Type | Primary Source Tools | Analysis Goal |
| Host-Based | EDR Agent, Memory Capture Tools | Process execution chains, file system changes, persistence mechanisms |
| Network-Based | SIEM (Firewall/Netflow logs), Packet Capture | Lateral movement, data exfiltration volumes, C2 communication |
| Log-Based | SIEM (Auth, App, Cloud logs) | User activity, access patterns, initial breach vector |
Determining the Incident Root Cause: Asking “Why” Until It Hurts
Determining incident root cause is the investigative payoff. It’s the answer to the question, “What do we need to fix so this doesn’t happen again?” Superficial causes are easy: “A user clicked a phishing link.” But true root cause analysis digs deeper. Why did the email get through the filter? Why did the user click it? Was the awareness training ineffective?
Methodologies like the “5 Whys” are useful here. You keep asking “why” to peel back the layers. Another powerful technique is causal factor charting, which visually maps out the sequence of events and conditions that led to the failure. The goal is to identify the underlying weaknesses in people, processes, or technology.
Was there a missing security control? A flawed procedure? An architectural weakness? Finding this core issue is what transforms a reactive incident response into proactive risk management and informs where to invest in security improvements.
Correlating Events in Incident Investigation: Connecting the Dots
In modern environments, attacks leave traces across dozens of systems. Correlating events in incident investigation is the art of stitching those disparate signals into a single story. An alert on one server is a data point; that same alert on ten servers, preceded by a spike in authentication failures from a single IP in your SIEM, is a campaign.
Effective correlation uses the SIEM as the central brain, ingesting logs from endpoints (EDR), network devices, cloud platforms, and identity systems. By writing precise queries or using built-in correlation rules, analysts can see relationships that are invisible in any single log source.
For example, correlating a suspicious PowerShell execution (from EDR) with an outbound connection to a new domain (from a firewall log) and a rare user login (from Active Directory logs) paints a clear picture of post-exploitation activity. This holistic view is critical for accurate scoping and effective containment.
Documenting Incident Investigation Findings: From Notes to Action
If it isn’t documented, it didn’t happen. Documenting incident investigation findings serves multiple critical purposes: it’s a legal record, a training tool, and a blueprint for improvement. The work isn’t done when the systems are clean. A formal report should tell the story chronologically, from detection to closure.
“Once the investigation is complete, hold an after-action meeting with all Incident Response Team members and discuss what you’ve learned from the data breach. This is where you will analyze and document everything about the breach. Determine what worked well in your response plan, and where there were some holes.” – SecurityMetrics
It must include the scope of impact (what systems/data were affected), the root cause analysis, a detailed timeline of events, and a list of all corrective actions taken. Using a consistent incident analysis reporting template ensures nothing is missed and allows for easy comparison across different incidents over time.
This documentation fuels the post-incident review, where the team asks the hard questions: What did we do well? What could we do better? What tools or training did we lack? These documented lessons are what close the loop and strengthen your security posture, turning a single incident into organizational learning.
Using SIEM and EDR in Tandem for Deeper Investigation
No tool is an island. Using siem edr investigation together creates a force multiplier effect. The EDR provides deep, granular visibility on the endpoint, what processes are running, what files are being touched, what network sockets are open.
The SIEM provides breadth and context, what’s happening across the entire network, in the cloud, and in authentication stores. The magic happens in the pivot. An analyst sees a high-severity alert in the SIEM dashboard about a potential brute-force attack.
With a click, they pivot to the EDR management console to see the real-time status of the targeted endpoint. They can examine running processes, kill a malicious one, and isolate the machine from the network, all from a single, correlated workflow.
This integrated approach, which we rely on to manage complex client environments, dramatically reduces mean time to detect (MTTD) and mean time to respond (MTTR), ensuring responses are both swift and informed.
Your Incident Analysis Reporting Template: What to Include

A good incident analysis reporting template provides structure without stifling necessary detail. It’s a living document that guides the reporting process. Here’s what a comprehensive one includes:
1. Executive Summary: A brief, non-technical overview of the incident, impact, and root cause.
2. Incident Timeline: A chronological table of key events from first precursor to final recovery.
3. Investigation Details: Scope, evidence sources, analysis methodology (e.g., MITRE ATT&CK mapping).
4. Root Cause Analysis: A clear statement of the underlying cause, supported by evidence.
5. Impact Assessment: Business, financial, technical, and reputational impact.
6. Corrective Actions: Specific, assigned actions to remediate the root cause and prevent recurrence.
7. Lessons Learned & Recommendations: Insights for improving process, tools, or training.
8. Appendices: IOCs, evidence hashes, full log excerpts.
FAQ
What should an effective incident investigation process include first?
An effective incident investigation process starts with scene protection and immediate action to secure the incident scene. The investigation team should collect photographic and video evidence, witness statements, and inspection reports early. Clear scene management prevents data loss.
From there, the team documents hazards and risks, reviews safety procedures, and begins structured evidence gathering to support accurate incident analysis and reporting.
How do you identify root causes after workplace incidents occur?
To identify root causes after workplace incidents, teams typically use Root Cause Analysis methods such as the 5 Whys, fishbone diagrams, and Fault tree analysis. Investigators review training records, safety rules, and equipment deficiencies while examining hazard sources.
Strong incident root cause analysis looks beyond human error to procedural deficiencies, management system gaps, and production pressures that contributed to the event.
Why are near misses important in incident investigation reports?
Near misses provide early warning signals that help safety officers strengthen the safety program before serious harm occurs. Including them in incident investigation reports improves incident statistics and supports continuous improvement.
Reviewing near misses helps teams spot hazards and risks, validate safety procedures, and implement preventive actions. Many high-risk industries treat near-miss tracking as essential to effective risk management.
What evidence should the investigation team collect on site?
At the accident site, the investigation team should gather witness statements, CCTV tapes, photographic and video evidence, and relevant inspection reports. They should also review personal protective equipment usage, safety devices, and equipment conditions such as conveyor belt systems or motor windings.
Strong evidence gathering supports credible investigation reports and helps meet safety regulations and regulatory agencies’ expectations.
Turning Analysis into Resilience
A security incident is a failure. A proper investigation is how you fix it for good.
By sticking to a process, from the first alert to final documentation, your team gets better. Each investigation makes your defenses stronger. The point isn’t just to solve “what happened,” but to stop it from happening again.
If your tools or workflows are making this hard, our consulting can help. We guide MSSPs to build stacks that support strong, repeatable response.
Let’s build your resilient stack
References
- https://presensi.perpusnas.go.id/press/1lgbhzh/perpusnas-mastering-accident-and-incident-investigation-a-comprehensive-guide-1764815002
- https://www.securitymetrics.com/blog/6-phases-incident-response-plan
Related Articles
- https://msspsecurity.com/operations-delivery-mechanisms/
- https://msspsecurity.com/security-incident-investigation-process/
- https://msspsecurity.com/soc-analyst-alert-investigation-steps/
- https://msspsecurity.com/steps-analyze-security-incident/
- https://msspsecurity.com/digital-evidence-collection-analysis/
- https://msspsecurity.com/determining-incident-root-cause/
- https://msspsecurity.com/correlating-events-incident-investigation/
- https://msspsecurity.com/documenting-incident-investigation-findings/
- https://msspsecurity.com/using-siem-edr-investigation/
- https://msspsecurity.com/incident-analysis-reporting-template/