Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM
Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM
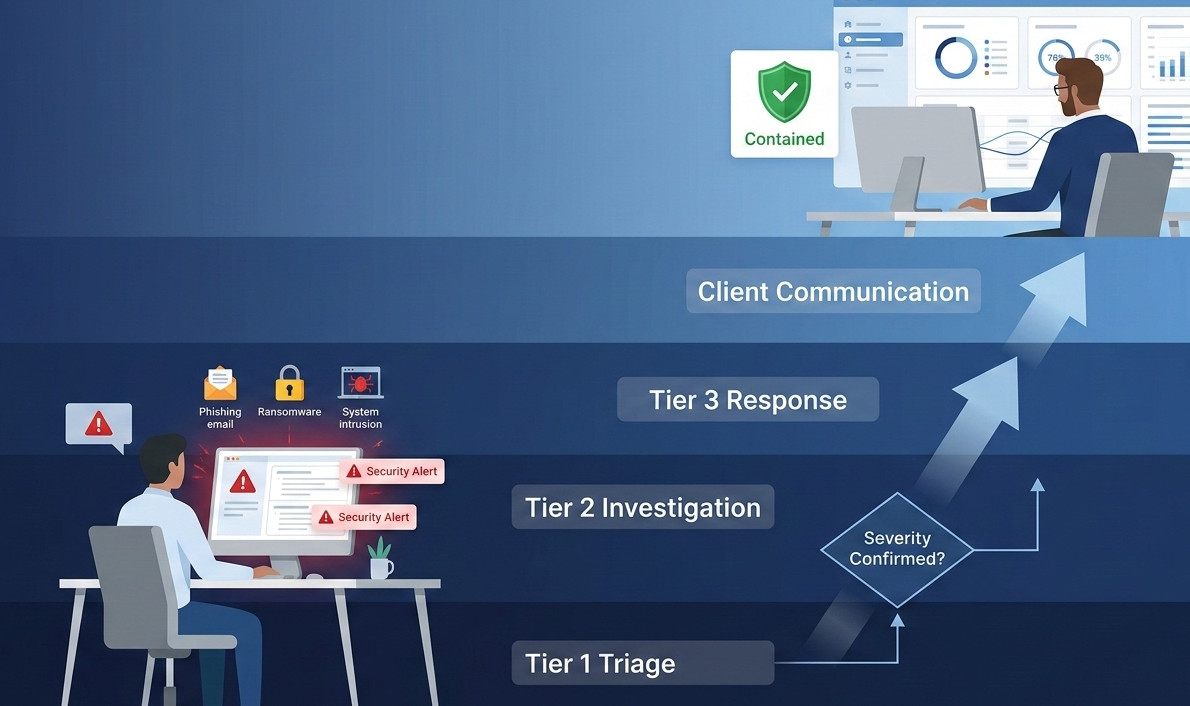
An MSSP incident escalation process is a specific workflow for moving a security alert from detection to the right expert quickly. This is the line between a contained event and a major breach. Without it, critical time gets lost in confusion. Minor issues can escalate. We’ve seen it: teams scrambling for a decision-maker while malware spreads.
A solid process is your circuit breaker. It’s your operational nervous system during a crisis. Here’s how to build one that will work in 2026, when threats move at machine speed. Your final defense is human judgment. Read on to secure your process.
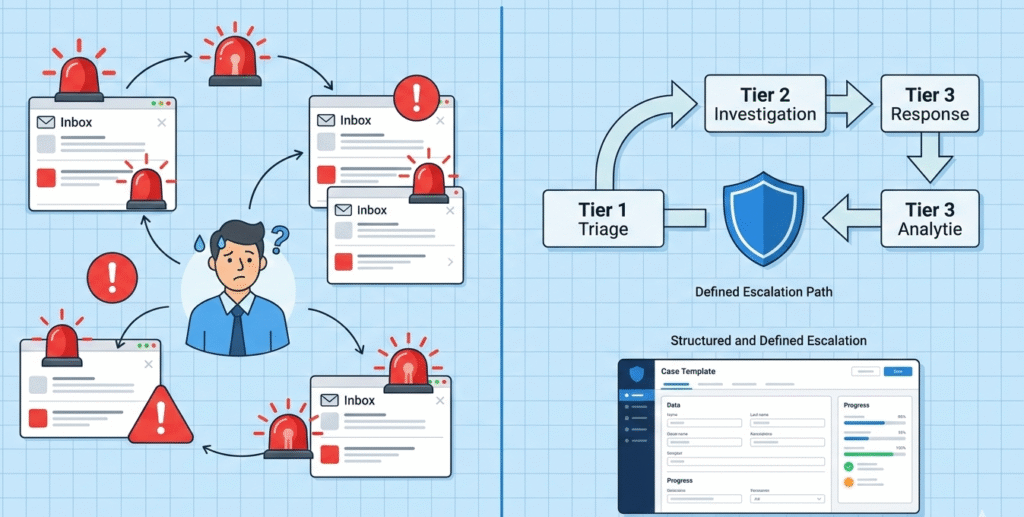
An MSSP escalation process is a structured workflow. It flags an unresolved security issue and pushes it to specialized engineers or management within strict timeframes. This structure turns ad-hoc panic into coordinated action. It’s the core of a managed security service provider’s promise.
“Alerting platforms for MSSPs can display and clearly split out alerts from multiple tenants, as well as building escalation policies that reflect the SLA requirements for different clients. The training must target the following four objectives: Engineers are aware of the escalation procedures and have all notifications set up correctly; They clearly understand the client’s infrastructure and know how to access it…” – N-able
Without it, you get ticket ping-pong. An alert bounces between teams while the threat dwells in your network. The business impact grows with every wasted minute. A defined process slashes the Mean Time to Resolve (MTTR) by making handoffs automatic and accountable.
We built ours because we watched clients suffer without one. A simple phishing email once languished for hours, deemed “low priority.” It wasn’t. The result was a costly data leakage incident. Now, every alert has a clear path.
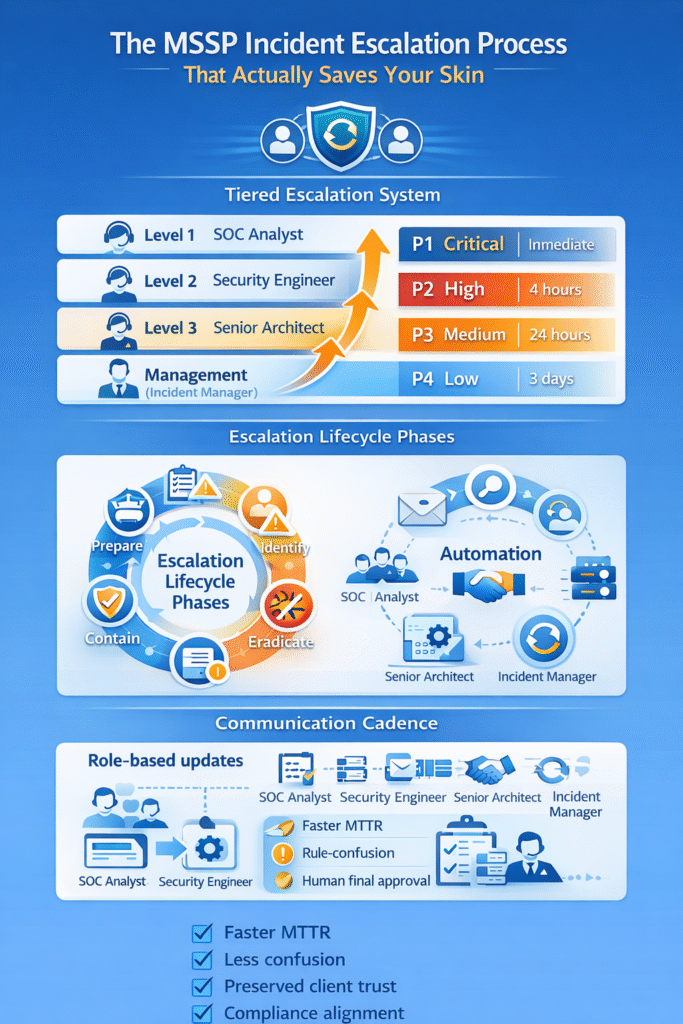
Most effective operations use a three-to-four tier system. Following structured incident escalation procedures categorizes events by technical complexity and business risk. This isn’t about bureaucracy, it’s about precision.
“Established procedures outline who to contact, how to report incidents, and expected response times. Escalation procedures are also in place to ensure that high-priority incidents receive prompt attention. The incident response team works with law enforcement agencies or third-party forensic experts to identify root causes and ensures a comprehensive and effective response.” – Check Point Software
Level 1 handles initial logging and basic triage. Think help desk or SOC analysts recognizing known Indicators of Compromise. If they can’t resolve it in a set window, the clock starts for a handoff. Level 2 is for security engineers doing deeper forensic analysis. They hunt for root cause.
Level 3 brings in senior architects or external vendor support for critical breaches. This tier deals with proprietary fixes and advanced persistent threats.
| Tier | Primary Owner | Scope | Typical Trigger |
| Level 1 | SOC Analyst | Initial alert review, basic IoC checks. | Alert detection from SIEM. |
| Level 2 | Security Engineer | In-depth investigation, containment actions. | Unresolved by L1 in 30 minutes. |
| Level 3 | Senior Architect | Critical breach response, forensic analysis. | Confirmed high-impact system failure. |
| Management | Incident Manager | Client comms, resource allocation, SLA tracking. | Breach of contractual response times. |
Credits: Jordan M. Schroeder
A severity matrix maps business impact to action, removing guesswork from a crisis. You categorize by user scope, data sensitivity, and regulatory exposure. Each level has a required response time.
“Critical” means a total outage or active data theft. That triggers a war room and maybe a 15-minute callback. “High” could be a major department down, with a four-hour resolution target. Medium and low issues follow with longer timelines.
We build this matrix with the client. A hospital’s “critical” is different from a shop’s. We once gave a generic plan to a public safety agency. It failed immediately. Their “sensitive data” definition was life-or-death.
The matrix decides who gets called at 3 a.m. and if you ring your insurer. Properly defining incident escalation triggers ensures the matrix remains the source of truth for urgency.
Escalation sits inside a broader incident response lifecycle; it doesn’t operate on its own. The familiar phases, Preparation, Identification, Containment, Eradication, Recovery, and Lessons Learned, create the structure.
In practice, escalation is what pushes an incident forward. Preparation is where communication trees and approval paths are defined. Identification is often the trigger point, when an alert is validated and the clock starts.
Containment can require fast executive approval. We’ve seen Level 1 analysts hesitate because tooling didn’t clearly define authority boundaries. As consultants to MSSPs, we audit those gaps when helping teams select and assess new platforms. Eradication and Recovery demand senior oversight, especially when product limitations surface mid-incident.
Lessons Learned closes the loop. When handoffs lag, we recommend workflow automation or product changes. Each review sharpens the next response.
Communication discipline keeps a technical incident from turning into a trust failure. Executing a security incident communication plan provides clients with clarity on impact, actions taken, and when they’ll hear from you next. Structured, role-based updates prevent confusion when pressure spikes.
Inside the SOC, cadence looks different. Engineers exchange rapid, technical details in dedicated channels. We’ve audited MSSPs where analysts paused containment to draft client emails. That imbalance slows response and increases risk.
Severity drives frequency. A P1 may require updates every 30 minutes; a P3 might warrant daily summaries. Automation within SIEM or SOAR tools can trigger status updates automatically, freeing analysts to focus on containment and investigation.
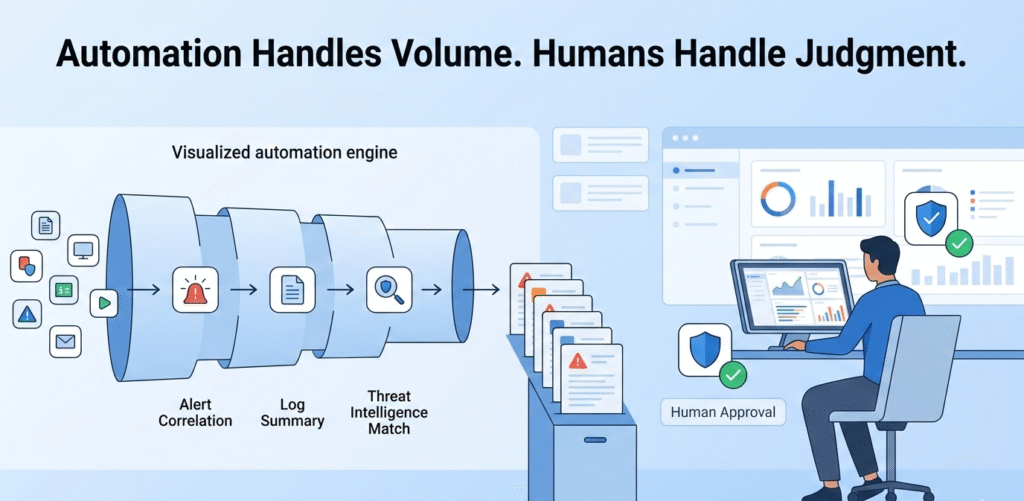
By 2026, automation is table stakes. The telemetry volume across cloud and hybrid estates makes manual triage unrealistic. Smart workflows should correlate alerts, summarize logs, and pull similar historical cases before an analyst even opens the ticket.
That filtering matters. We’ve worked with MSSPs drowning in false positives, where engineers spent more time clearing noise than investigating risk. The right tooling reduces that drag and can trigger escalation automatically, like raising severity when a critical patch fails.
Still, judgment stays human. We advise clients to require engineer approval for containment actions. Automation enforces accountability, like our 15-minute reassignment rule, but people make the final call.
An mssp incident escalation process goes beyond basic incident response. A Managed Security Service Provider builds structured handoffs inside security operations, with defined response times and ownership at each tier.
It connects threat detection, detection and response, and incident management into one path. Unlike a simple response plan, it protects client environments, sensitive data, and limits reputational harm during a cybersecurity incident.
Clear escalation paths reduce confusion during cyber threats. Instead of debating next steps, teams follow a defined incident response process with preset response actions. Automated alert signals from SIEM (security information and event management) systems support faster threat detection.
Structured escalation ensures forensic analysis starts early, limiting data breaches, ransomware attacks, and data leakage incidents before business continuity is affected.
An escalation workflow must reflect regulatory frameworks like ISO 27001 and PCI DSS. The incident response plan should define documentation standards, chain of custody rules, and incident report requirements.
Strong incident management protects sensitive data and supports cyber insurance claims. Aligning escalation with compliance keeps cybersecurity services audit-ready and reduces legal risk after a cyber breach.
Threat intelligence guides prioritization. Threat intelligence feeds and investigation history help teams assess whether a security event signals advanced persistent threats or a minor phishing email. Integrated threat intel feeds inside SOC-based operations improve detection and response accuracy.
This context shapes response actions, forensic tools usage, and containment steps within the broader incident response framework.
Build your unbreakable escalation process. Start with your tiers and severity matrix, agreed with your client. Put communication in every step. Use automation to help, not replace.
Test it hard. Run tabletop drills for ransomware and phishing. Find the weak spots. The process that survives a drill will survive a real breach. We built our consulting on this framework. We know the panic of a broken process. The goal is a calm, precise response.
Audit your own process. Map your alerts. Time your handoffs. Find the cracks. Then start building. Build it with us.
