Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM
Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM

Alert fatigue is the slow, grinding burnout that happens when your security team drowns in a sea of meaningless notifications. It’s not just about volume, it’s about value. When analysts face thousands of alerts daily, with a staggering 99% being false positives, critical threats get missed.
The cost is measured in burnout, attrition, and breaches. This isn’t a tool problem, it’s a signal problem. Keep reading to learn how to filter the noise and let your team focus on what truly matters and reducing alert fatigue SOC.

You see the numbers. Ten thousand alerts a day. Maybe more. The screen blinks endlessly, a river of red and orange. At first, there’s urgency. Every ping demands attention. Then, weeks in, a numbness sets in. It’s not laziness, it’s cognitive overload. The brain, faced with constant, low-value stimuli, starts to filter. It has to. The danger is what it filters out.
“Reducing alert fatigue is not just about having fewer alerts, it’s about more efficient processes. By implementing strategies such as intelligent prioritization, leveraging AI automation, enriching alerts with context, and customizing your detection mechanisms, you can significantly cut through the noise.” – Swimlane
That one alert, buried on page three, might be the real one. We’ve seen it happen. Analysts, good ones, become skeptics of their own tools, which is a terrible place for a defender to be. The operational cost is immense.
Credits: dvd
It’s easy to blame the tools. The new endpoint solution is too chatty. The cloud platform logs everything. But the core drivers are usually process gaps. Tool sprawl creates isolated data silos.
An EDR fires, the SIEM pings, and the identity system flags, all for one user action. Without a refined alert triage prioritization process to correlate these signals, that’s three separate alerts.
Detection rules are set once, often by a vendor’s default, and never revisited. They aren’t tested against your actual, normal traffic. So they scream about routine business activity.
This creates a self-defeating cycle where analysts spend hours daily on manual triage, leaving no time for a comprehensive MSSP alert handling process review that would identify and fix the root causes.
Think of your detection rules like the code running your business applications. You wouldn’t push untested code to production. So why push untested detection logic to your SOC? A Detection-as-Code (DaC) methodology applies software engineering rigor to security. Rules are written, version-controlled, and peer-reviewed in a development environment.
They are tested against historical or synthetic data to see what they would have caught, and more importantly, what benign activity they would have falsely flagged. This pre-deployment validation is powerful.
One organization using this approach saw a 90% reduction in investigation time simply because the rules reaching their analysts were high-fidelity by design. It transforms rule management from an ad-hoc chore into a disciplined, measurable practice.
| Strategy | Core Action | Direct Fatigue Impact |
| Pre-Deployment Testing | Validate rules against sample data before enabling. | Eliminates “chatty” rules at the source. |
| Version Control | Track all changes and enable easy rollbacks. | Prevents “bad tune” days from causing chaos. |
| CI/CD Pipelines | Automate testing and deployment of rule sets. | Ensures consistency and saves engineering time. |
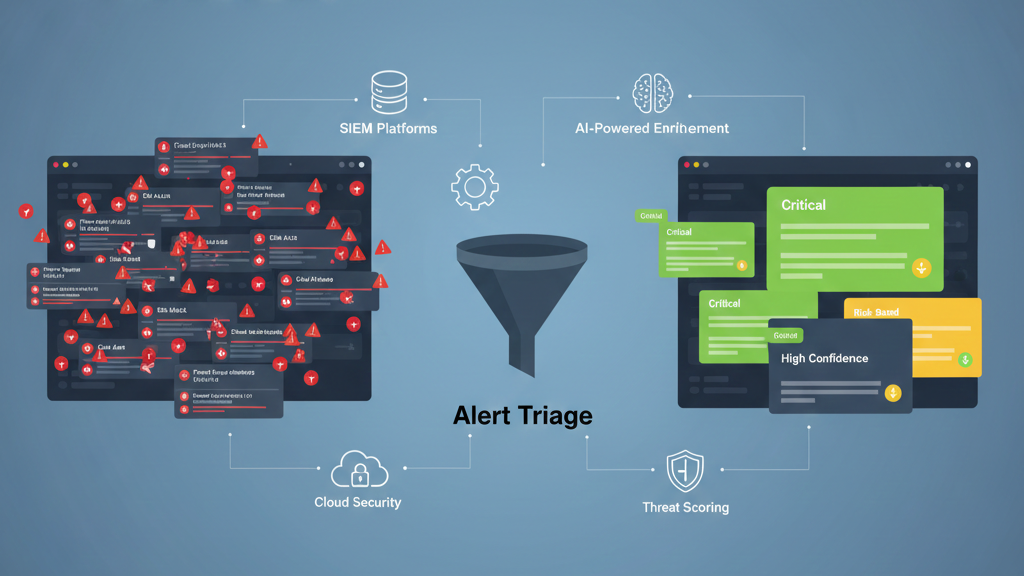
Once your rules are sharper, you need layers to manage the flow. The goal is to present a prioritized work queue, ensuring the MSSP alert triage process is explained through clear, contextualized steps rather than a raw firehose.
First, correlation. Group related alerts, like a suspicious login, a file download, and an outbound connection, into a single incident ticket. This alone can cut volume significantly.
Next, enrichment. Automatically pull in context: How critical is the affected asset? Is the user in a privileged group? Does this I.P. match a known threat feed? An alert with a high-risk score attached demands attention. A low-score alert might be handled by an automated playbook.
For lean teams, this orchestration is not a luxury. It’s what allows you to cover 100% of alerts without adding headcount. Automation handles the predictable, analysts handle the exceptions.

Let’s be clear. AI isn’t a magic bullet that replaces your team. It’s a force multiplier for the analysts you have. Modern, agentic AI systems can do more than run static playbooks. They can perform recursive reasoning. They look at an alert, gather initial evidence, and decide what to do next based on what they find, just like a human would.
“The ability to address security monitoring is a key requirement. Without high-fidelity alerts that correlate events effectively, security teams find themselves spending too much time investigating false alerts. To help address these problems, MSSPs must provide customers with aggregated alerts enriched with context that reduce false positives, while also helping to define, guide, and accelerate investigations.” – Fortinet
They can safely close out false positives with detailed notes. They can escalate true positives with a compiled evidence package. This isn’t about black-box decisions. It’s about handling the repetitive, time-consuming legwork of Tier 1 triage.
For an MSSP Security team, this capability is transformative. It allows us to scale our vigilance, ensuring every client’s alerts receive consistent, thorough initial analysis, day or night, without burning out our people. It lets analysts act as investigators, not data clerks.
You can’t manage what you don’t measure. But be careful what you worship. A dropping “total alert count” is a vanity metric if you’re just blindly suppressing signals. Better metrics focus on outcomes and health. Track your Alert-to-Incident Ratio. If less than 20% of alerts become investigable incidents, your noise floor is too high.
Monitor Mean Time to Acknowledge (MTTA) and Mean Time to Resolve (MTTR) for your highest-risk alerts. These should trend down. Perhaps most importantly, track analyst satisfaction and turnover.
Are your people less stressed? Are they staying longer? These human metrics often tell the true story of your program’s sustainability. They prove your fatigue reduction efforts are working where it counts.
Start by reviewing your alert management process inside the Security Operations Center. Many teams suffer from alert overload because detection rules and alert thresholds are too broad.
Tighten alerting rules, remove duplicate security alerts, and focus on high-risk signals. Clear workflows help Security Teams cut noise and begin reducing alert fatigue soc without missing real threats.
False positives force security analysts to investigate harmless activity again and again. Over time, this leads to analyst burnout and weak incident response.
When detection systems create too many faux positifs, real malicious activity can hide in the noise. Improving threat scoring, using better contextual information, and tuning detection rules reduces alert fatigue and supports cybersecurity professionals.
Risk-based alerting ranks security alerts by business impact and threat level. Instead of reacting to every firewall trigger or endpoint event, Security Teams focus on alert prioritization.
Combining threat intelligence feeds, asset management data, and Identity systems supports smarter alert triage. This reduces cybersecurity alert fatigue and strengthens your overall security posture.
Yes, when used correctly. Machine learning, Behavioral Analytics, and Artificial Intelligence help filter low-value incident alerts and highlight alertes critiques. AI-powered enrichment and triage automation add context before analysts review a case.
With proper alert thresholds and oversight, AI-powered solutions reduce Security Alert Fatigue without replacing human security professionals.
Reducing alert fatigue is continuous operational hygiene. It begins by admitting the current state is unsustainable. It moves forward by treating detection logic carefully, adding intelligent automation, and always measuring the impact on your team’s focus.
The goal is a clear SOC, not a chaotic one. Tools should serve the analysts. Your team should hunt threats, not sort through noise.
This shift starts with the next alert you tune and the next process you automate.
For expert guidance, our consulting helps MSSPs with vendor-neutral product selection, auditing, and stack optimization. Let’s build your operation.
