
Your security tools are working. They’re generating the alerts. The real breakdown happens in the silent minutes after, when an analyst isn’t sure who should act. Most security incidents fail at escalation. Signals rot in queues while attackers, like SCATTERED SPIDER or Volt Typhoon, move laterally.
We see this daily in security operations. The problem isn’t finding the threat, it’s mobilizing the right people fast enough to stop it. A structured escalation framework is your only defense against this dead time. Keep reading to learn how to build escalating critical security events that actually works
What You Should Remember
These key points highlight how teams can avoid delays and keep incident response moving when serious threats appear.
- Define Unambiguous Triggers: Move beyond generic “critical” labels to specific conditions, like data exfiltration over 1GB or a compromised Domain Controller, that force immediate handoff.
- Automate the Handoff: Use AI technologies and integrated platforms to dynamically score and route alerts based on asset value, stopping manual hesitation.
- Own the Entire Chain: Assign clear, accountable ownership for each escalation level, from initial alert triage to executive crisis management, and test it regularly.
The Silent Killer in Your SOC
You’ve invested in the SIEM alerts, the threat intelligence feeds. Your dashboard lights up with warnings. But in those crucial next moments, uncertainty creeps in. The Level 1 analyst wonders if it’s truly urgent. They might think Level 2 is already on it. Level 2, swamped, assumes it’s not critical.
The on-call engineer hesitates. This is where incidents fail. It’s not a tools problem. It’s a human coordination gap, magnified in complex hybrid cloud environments. By the time ownership is clear, the impact is already real, data gone, systems encrypted. We build processes to close this gap.
Security teams drown in noise. Without a clear path, urgency dissipates.
- Alerts languish in triage queues.
- Lateral movement goes unchecked.
- SLA clocks tick toward breach.
The MITRE ATT&CK framework maps the adversary’s playbook, but your escalation plan is your team’s counter-play. Without it, you’re just watching the game.
How to Define What “Critical” Really Means
Credits: Nguyen Le Vu
The word “critical” has lost all meaning in a security operations center. An alert critical on a test server is not the same as one on a SCADA system. You need escalation triggers so specific they bypass debate, removing the ambiguity that often leads to analyst hesitation during a breach.
Think in terms of concrete, measurable events that signal a direct threat to business survival. This moves you from reactive to proactive response.
- Technical Triggers: A confirmed IoC on a crown jewel asset (like a Domain Controller). Data exfiltration exceeding a set threshold, say 1GB. A pattern of failed logins from a high-risk IP followed by a success.
- Operational Triggers: Any incident involving executive (VIP) accounts. A ransomware encryption event. A violation of a strict compliance SLA, like the SEC’s 4-day reporting window.
This list isn’t generic. It must be tailored to what your organization values most. For an MSSP, this means co-developing these triggers with each client, because their crown jewels are unique.
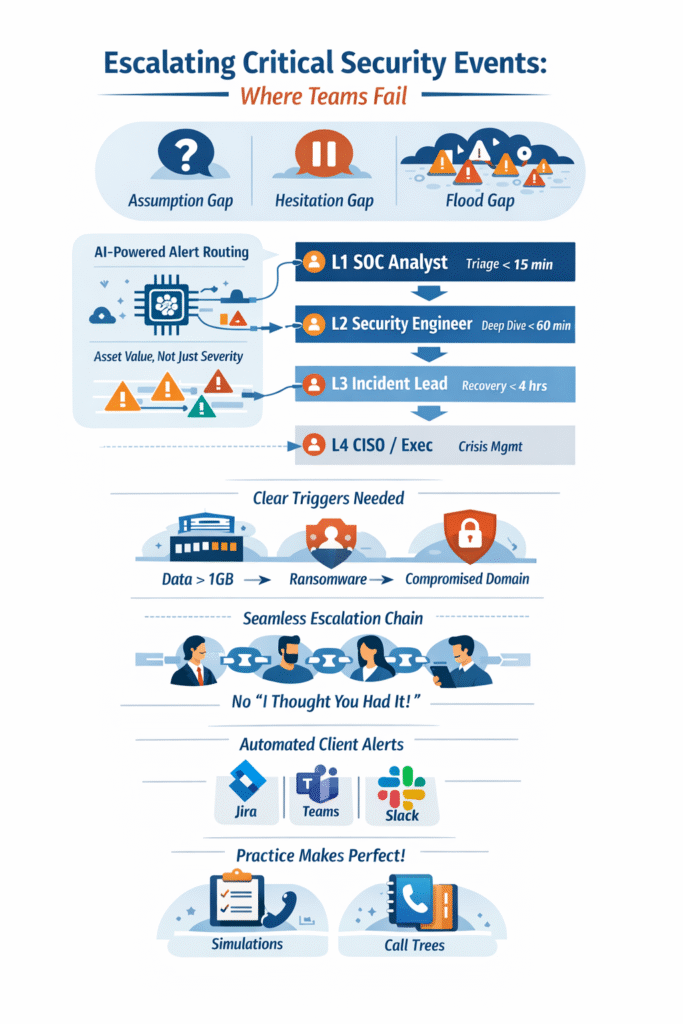
The 4-Tiered Escalation Model That Prevents Burnout
A tiered model isn’t about hierarchy. It’s about efficient resource allocation. It prevents your most expensive Security Analysts, the Tier 3 incident leads, from being buried in noise, while ensuring the most severe incidents get executive visibility fast.
The goal is a smooth, predictable flow, ensuring that established incident escalation procedures are followed at every stage to maintain consistency.
“Security service levels should go beyond traditional metrics to include time to detect and classify threats, speed of escalation for critical security events, the frequency of vulnerability assessments and penetration testing and time to implement security patches and updates.” – MSSP Alert
| Escalation Level | Primary Actor | Focus & Authority | Target Engagement Time |
| Level 1 | SOC Analyst | Initial alert triage, validation, and false positive filtering. | Immediate. Goal is sub-15 minute initial assessment. |
| Level 2 | Security Engineer | Deep analysis, initial containment steps, and threat hunting. | Under 60 minutes if L1 cannot resolve. |
| Level 3 | Incident Lead / SME | Full incident coordination, eradication, and recovery guidance. | Under 4 hours for major incidents. This is the crisis quarterback. |
| Level 4 | CISO / Legal / Execs | Crisis management, external communications, and regulatory disclosure. | Variable, based on legal and PR requirements. |
The handoff between each level is the fragile link. A documented alert triage workflow in a co-managed portal ensures nothing is lost in translation. The Reference number, actions taken, and IoCs move up the chain with the ticket.
From Manual Mayhem to AI-Powered Flow
Legacy escalation runs on static matrices and tribal knowledge. It collapses under modern alert volume. The new approach uses context. AI technologies can analyze an alert’s context, which user, what asset, what behavior, and assign a dynamic risk score. This score, not a static severity tag, dictates the escalation path.
A “High” alert on a non-critical workstation might stay with Tier 1. A “Medium” alert on your main financial database? That gets auto-escalated to Tier 2. This is risk-based alerting. It respects the reality that not all “critical” alerts are created equal.
Platforms now offer end-to-end integration that can even trigger autonomous containment, isolating a host before a human logs in. This cuts the attacker’s free runway from hours to seconds.
We implement this by layering intelligence. Correlating SIEM data with vulnerability management states and user behavior analytics. The system begins to understand normal, making the abnormal, the true threat, stand out starkly and move up the chain fast.
The Ownership Gaps Where Your Process Fails
You can have the best runbooks. The escalation paths can be beautifully drawn. But if people don’t feel ownership, the system fails. The most common breaks are in the seams between tiers. The “I thought you had it” moment. This is especially acute for MSSP teams managing client infrastructures, where context switching is constant.
“Reviewing daily security reports, identifying anomalies, and escalating critical security events as necessary. Conducting thorough investigative actions based on security events and following standard operating procedures for remediation.” – Shine
- The Assumption Gap: L1 assumes L2 is monitoring the dedicated channel. L2 assumes the alert wasn’t urgent. This is the “signal rot” described in frontline forums.
- The Hesitation Gap: On-call staff, paged at 3 a.m., second-guess the severity. They wait, hoping the day shift will handle it. Attackers don’t sleep.
- The Flood Gap: Dumping 500 “Critical” alerts on a Friday night creates an endless treadmill. Analysts burn out, and real threats get lost in the noise.
The fix is cultural as much as procedural. Clear, written protocols. Blameless post-mortems. And most importantly, regular tabletop exercises that make the escalation muscle memory, not a forgotten checklist.
Building an Unbreakable Chain for MSSP Teams
For an MSSP, escalation is a dual-layer challenge. Optimizing a mssp incident escalation requires aligning external client expectations with internal SOC capabilities. The key is transparency and co-development.
- Co-Develop Playbooks: Don’t deliver a generic matrix. Build escalation triggers with the client, based on their critical infrastructure assets, compliance needs, and internal contacts.
- Automate Client Notification: Use integrated workflows to open tickets directly in the client’s Jira Service Management or notify their team lead via Microsoft Teams or Slack, with all context attached.
- Practice Relentlessly: Conduct quarterly incident simulations. Test the “call tree.” Validate that the client’s CISO gets the notification you think they do. These drills reveal the breaks before a real incident does.
The goal is to act as a true extension of the client’s team. When our security network detects a critical event for a client, the escalation should feel frictionless to them, the right expert is engaged, with the right information, at the right time. That’s how you build trust and, more importantly, how you contain breaches.
FAQ
How do cyber threats affect escalating critical security events today?
Cyber threats continue to evolve across the global threat landscape, especially in the United States where attackers target critical infrastructure and supply chains. When escalating critical security events, security teams must understand how these threats operate and spread.
Strong threat intelligence, clear alert escalation processes, and fast incident response help security analysts react quickly and reduce damage from advanced attacks.
Why do security teams struggle with alert escalation during incidents?
Security teams often face hundreds of security alerts every day from different security tools. Without strong alert categorization and a clear alert triage workflow, analysts may delay escalating critical security events.
Security operations centers must organize alert management carefully, prioritize SIEM alerts correctly, and ensure the support team knows when to escalate issues to prevent serious incidents.
How can artificial intelligence improve alert triage and escalation?
Artificial intelligence helps security operations process large volumes of alerts faster than manual review. AI technologies can assist with alert triage, analyze IP address activity, and highlight suspicious behavior across hybrid cloud environments.
By combining threat intelligence with automated alert categorization, security teams can escalate critical security events sooner and reduce delays in the incident response process.
What role does threat intelligence play in security event escalation?
Threat intelligence helps security analysts understand attacker behavior and emerging cyber threats in the threat landscape. Information about groups like SCATTERED SPIDER or activity targeting supply chains can help teams decide when to escalate alerts.
When used correctly, threat intelligence strengthens security posture, supports incident response decisions, and improves the speed of alert escalation across security operations.
Stop Letting Threats Linger in Queue
Threats don’t wait for internal alignment. Groups like Salt Typhoon exploit hesitation between detection and action. Escalating critical security events quickly turns scattered tools and analysts into a coordinated defense.
Define clear triggers, assign ownership across escalation tiers, and automate the process to remove doubt. If you want expert guidance to strengthen your security operations and tool stack, MSSP Security offers consulting to streamline workflows and improve response. Join MSSP Security Consulting Services.
References
- https://www.msspalert.com/native/service-levels-for-mssps-elevating-security-specific-services
- https://www.shine.com/jobs/sr-information-security-engineer/bmc-software-inc/18702463