You can’t fight every fire at once. How security alerts are prioritized is the triage system that stops your team from drowning in noise and focuses them on the real breaches. It’s the difference between chasing false positives and neutralizing a ransomware attack before it encrypts your data.
This guide explains the practical system we use to separate critical threats from background chatter. Keep reading to learn how to implement it and reclaim your team’s focus.
Priority Signals That Actually Matter
- Prioritization hinges on three core factors: the technical severity of the alert, the business value of the affected asset, and the real-world likelihood of an attack succeeding.
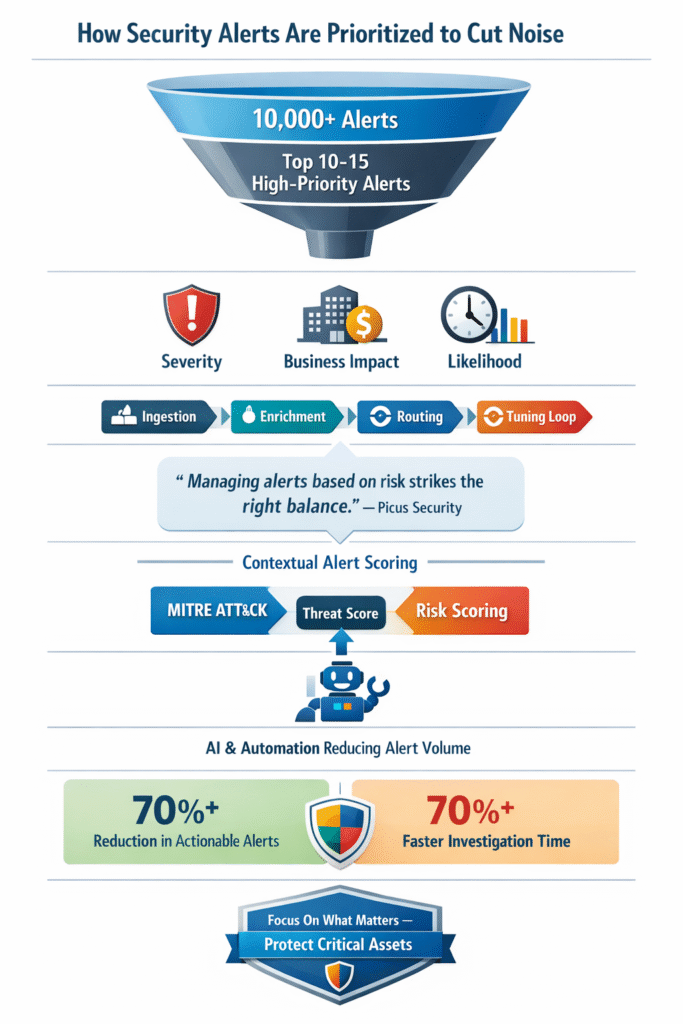
- Frameworks like MITRE ATT&CK and risk scoring models turn subjective guesswork into a consistent, defensible process for the entire team.
- Effective implementation is a cycle, not a one-time setup. It requires continuous tuning of detection rules and leveraging automation to handle repetitive tasks.
Why Your Team Is Drowning in Alerts

The numbers don’t lie. A typical security team might see over 10,000 alerts per day. The human brain can’t process that. You glance at a dashboard flashing red, your eyes glaze over, and something in you just tunes out.
That’s alert fatigue, and it’s not a personal failing. It’s a system failure. When every alert screams “critical,” none of them are. Seeing the mssp alert triage process explained through a structured lens reveals.
“The most effective way to deal with this heavy load is to understand security event patterns, categorize and prioritize accordingly, and deal with categories as a whole. … Managing alerts based on risk is key for striking the right balance.” – Picus Security
The cost is real. Teams waste cycles investigating low-risk issues. A phishing email sent to a generic marketing alias gets the same scrutiny as a privileged domain admin account logging in from a new country at 3 AM. The important signals get lost in the noise. Burnout sets in. Good analysts leave.
The security posture weakens because the team is busy, but not effective. We see this pattern often when new clients first engage with our MSSP security services. The first step is always turning down the volume.
What Actually Makes an Alert High Priority?
Credits: Cloud Stack Studio
We often see vendors slap a “high” or “critical” label on alerts, but those tags are usually meaningless on their own. Real prioritization needs three things: severity, impact, and likelihood. Remove one, and the whole system fails.
Consider a critical flaw on an internet-facing server with customer payment data. That’s an emergency. Now, take that same critical flaw and put it on an old printer in a locked closet. It’s barely a footnote for the next maintenance window. The context defines the risk.
Here is a simple way to break it down:
| Factor | High-Priority Scenario | Low-Priority Scenario |
| Severity | Active exploitation of a privileged account. | A blocked malware download on a standard user’s laptop. |
| Business Impact | An alert affecting the e-commerce payment gateway. | An anomaly on an internal test server with no customer data. |
| Likelihood | An unpatched, weaponized CVE on a public-facing system. | A theoretical vulnerability on a system behind multiple security controls. |
The goal is to find the alerts where all these factors intersect. That’s where you direct your people. Everything else gets handled by automation, scheduled for later review, or tuned out of the system entirely. It’s not about catching everything. It’s about catching the things that matter.
The Frameworks That Give Triage Structure
How do you get consistent judgment from a whole team, especially at 2 AM? You can’t just wing it. You need a playbook. That’s where industry frameworks come in, giving everyone a shared language and structure. We find the MITRE ATT&CK framework to be invaluable for this. It lets analysts map a suspicious event to a known adversary tactic.
Take an alert for “unusual PowerShell execution.” Alone, it’s just noise. But if that execution is followed by a call to a known malicious server, and it maps to ATT&CK technique T1059, the situation becomes serious. The framework provides the missing context.
We also lean on standardized risk scoring to remove debate. A model assigns points for:
- Asset value and data sensitivity
- Attack severity
- Threat intelligence context
An alert scoring 95 gets an immediate call. One scoring 15 is auto-closed. In our audits, we see too many tools use generic scoring. We help MSSPs layer their own intelligence on top, ensuring the score reflects the real threat landscape, not just a vendor’s static rules.
Building Your Prioritization Workflow
Understanding theory is one thing. Making it operational is another. A real alert triage prioritization process is a loop, not a line. It begins with ingestion into a central platform like a SIEM.
“Attack chain detection prioritizes based on asset value, a compromised domain controller triggers immediate escalation, while a test environment compromise might warrant monitoring but not emergency response. This business context prevents both overreaction and underreaction.” – eSentire
The critical step is enrichment. The system adds vital context automatically: the asset owner, its network location, data sensitivity, and live threat intelligence. This turns a generic alert into a scored event based on your framework.
Finally, you route. High-priority alerts go to senior analysts. Medium scores go to a general queue. Low scores are logged for review. The loop must close. Every investigated alert is a lesson. Was it a false positive? Tune the rule. A true positive on a minor asset? Adjust your scoring. This cycle of tuning and testing transforms a noisy system into a precise one. We help MSSPs establish this, often reducing their actionable alert volume by over 70%.
Lessons From the Front Lines

Talk to a seasoned analyst and you’ll hear a consistent, gritty truth: tuning beats tools. A fancy new platform with default rules will drown you. A simple, well-tuned system with half the features will actually let you sleep.
The community is brutally pragmatic. They only care about alerts that are actionable. If an alert doesn’t tell you what to do next, or if you know you can’t fix the issue, it’s just noise. You kill it. There’s a strong pushback against over-complication. We hear it all the time: “Don’t over-business it. Figure out why you have so many open alerts first.”
crisis.The security posture weakens because the team is busy, but not effective. We often identify these bottlenecks during a mssp alert handling process review when new clients first engage with our services.
Now, the shift is towards what some call “defensive AI.” The goal isn’t to replace analysts, but to handle initial correlation. Can the system stack related alerts into one incident? Can it write a plain-English summary of the attack chain? This lets analysts look at the broader narrative, moving from reactive triage to proactive hunting.
FAQ
How do Security Teams reduce false positives during alert prioritization?
Security Teams reduce false positives by tuning detection rules and enriching security alerts with contextual information. Most cybersecurity teams combine threat intelligence, Behavioral Analytics, and asset context to validate events before escalation.
This approach strengthens alert management, lowers Alert Fatigue, and helps Security Operations Centers focus on real cyber threats instead of chasing harmless security incident noise.
What role does threat intelligence play in alert triage workflows?
Threat intelligence gives alert triage the real-world context it needs. By correlating threat intelligence feeds with alert severity, Security Operations Centers can identify active cyber attack patterns faster. This improves incident response decisions and helps cybersecurity professionals map activity to the MITRE ATT&CK framework.
The result is clearer prioritization across the evolving threat landscape and stronger threat detection accuracy.
How can automation improve alert management without overwhelming analysts?
Automation works best when guided by risk-based prioritization and auto-triage rules. Modern security platforms use Artificial Intelligence and SOAR Platforms to enrich Automated security messages and trigger alert escalation only when needed. This reduces analyst burnout and improves Analyst Workload balance.
With proper Alert Tuning, cybersecurity teams maintain control while still accelerating incident response and security response workflows.
Why is asset context critical when scoring security alerts?
Asset context connects the alert to business risk. Security systems that factor in attack surface exposure, endpoint security posture, and cloud security importance can assign smarter risk levels. Many teams use an alert scoring system with asset context score inputs to guide Risk prioritization.
This method helps prioritize security breach risks tied to high-value systems over low-impact activity.
Making Prioritization Your Reality
Effective alert prioritization is a core skill, not a luxury. It begins by accepting you can’t treat every alert the same. Focus on what truly matters: your most critical assets, data, and services. Build a process, not just a toolset, define risk factors, apply context, and implement scoring.
If the volume feels overwhelming, the process needs fixing, not the team.
For expert guidance on building this capability, our consulting helps MSSPs with vendor-neutral product selection, auditing, and stack optimization. Let’s build your strategy.
References
- https://www.picussecurity.com/how-to-improve-alert-management
- https://www.esentire.com/blog/from-10-000-alerts-to-10-stories-how-correlated-attack-chains-can-help-beat-soc-burnout