Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM
Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM

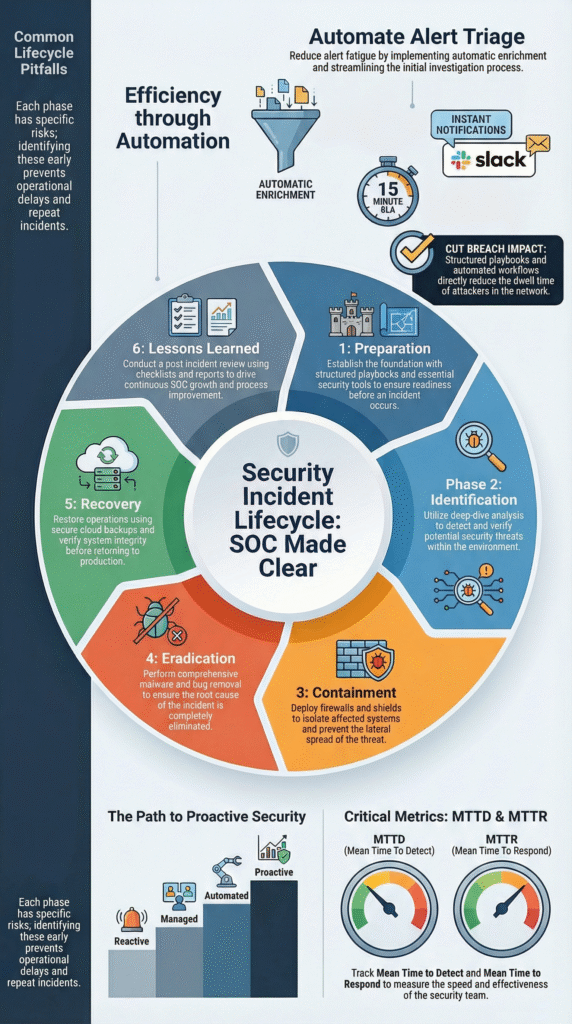
Security incident lifecycle SOC is the structured path a SOC follows to handle threats from start to finish. Most teams model it on NIST SP 800-61, covering preparation, detection, containment, eradication, recovery, and lessons learned. In our work with MSSPs, we often see strong tools but weak flow.
A clear lifecycle keeps shifts aligned, builds audit trails, and shortens response time. Breaches still average months before containment, which shows how much process matters. When teams track MTTD and MTTR and follow a shared playbook, incidents become manageable instead of chaotic. Keep reading to see how each phase works in practice.
This section captures the most important lessons from how the lifecycle works in real SOC environments.
Most SOCs follow six core phases: Preparation, Identification, Containment, Eradication, Recovery, and Lessons Learned. Each phase has a clear goal and usually maps to Tier 1–3 ownership. In practice, the flow looks simple on paper but messy in real environments.
| Phase | Main Goal | Typical Tools | Common Pitfall |
| Preparation | Build readiness with playbooks and tools | SIEM, EDR, SOAR | Runbooks no one has updated |
| Identification | Confirm if an alert is real and its impact | Log analysis, threat intel | Alert fatigue hides real threats |
| Containment | Stop spread fast | Segmentation, isolation | Overreacting and breaking ops |
| Eradication | Remove root cause | Forensics, malware analysis | Missed persistence |
| Recovery | Restore safely | Backups, validation checks | Reinfection from dirty backups |
| Lessons Learned | Improve process | RCA reports | Skipping the review |
From what we see working with MSSPs, preparation separates calm teams from chaotic ones. We often help providers test tools and playbooks before incidents hit, especially when evaluating new security stacks.
Analysts triage nonstop, and without good tooling, signal gets buried. We’ve seen teams improve clarity by aligning alerts to attacker behavior models and tightening product integrations during audits.
Someone leads, others dig deep, and documentation matters. When teams combine the right tools with disciplined reviews, each phase becomes faster and far more predictable.

When alerts live in one system, emails in another, and notes are in a chat app, analysts waste time juggling windows instead of investigating. We advise our MSSP clients to build their workflows so that an alert automatically creates a case file.
That case then moves through states, like Triage, Contained, Resolved, using automated playbooks. Those mirror a practical security operations center workflow used in mature environments.
Good tracking includes a few non-negotiable items:
Research from groups like ISC² shows that analysts often face alert noise levels of 90%. Centralized tracking is the only way to cut through that noise and see what’s actually important.
Modern platforms combine detection and response, so an analyst can investigate and contain a threat from one screen. This is crucial for clean handoffs between shifts and for understanding the full story of an attack.
Detection fails because of blind spots. Triage fails because of a lack of context.
If you’re not collecting the right logs, from your endpoints, cloud services, and network, you simply won’t see the attack. We often find gaps in cloud audit logs or incomplete endpoint telemetry during our audits for MSSPs.
An attacker can move sideways through your network unseen, even in teams that believe they fully understand inside an MSSP SOC workflow.
Then there’s human fatigue. Studies point to high stress and burnout rates among analysts, driven by a constant flood of low-quality alerts. They’re forced to make quick decisions at 3 AM with incomplete information.
Common breakdowns we see include:
Better technology alone won’t fix this. It requires disciplined logging, integrating data sources to provide context during triage, and building a process that guides analysts, not overwhelms them. When triage has context, escalation becomes a logical step, not a frantic search for help.

Effective containment happens in minutes. It isolates the compromised device or user account to limit the damage. Eradication is thorough, using deep forensics to ensure the attacker is completely removed.
Short-term containment is about speed:
Long-term containment keeps the environment stable while the forensic team does its work. This involves capturing disk images, analyzing memory, and piecing together a timeline of what happened.
Take ransomware. Recent data shows dwell time, how long the ransomware is inside before detonating, is now often under five days. You have to contain fast.
Real eradication means verifying the fix:
Tools like forensic suites and behavioral analytics confirm the attacker is really gone. Skipping these checks is how you get hit again by the same attack a week later. Containment stops the bleeding, but eradication is what actually heals the wound.
Credits: Cyber Gray Matter
Teams skip it because they’re tired. Once the systems are back online, the pressure is to close the ticket and move to the next alert.
But this is where real improvement happens. NIST stresses that this phase is critical for maturing your security program. Groups that do structured reviews consistently find they get better at detecting threats.
The excuses are always the same:
Research from USENIX Security Symposium shows,
“A majority of participants [breach attorneys] discourage investigators from producing formal reports or putting remediation steps into writing. When reports are written, some lawyers review and suggest changes that reduce culpability for the victim firm, such as by obfuscating root causes and corrective actions that could have prevented the incident… Lawyers typically advise against sharing written findings.” – USENIX Security Symposium
The MSSPs we work with that excel at this schedule a review meeting within two weeks of closing a major incident. The lessons learned directly feed back into the Preparation phase, creating a true cycle of improvement.
The shift happens by building on the lifecycle. Finally you use intelligence to hunt for threats before they cause alerts. Teams that successfully make this leap usually rethink not just tooling but also how analysts understand how does a SOC operates daily in real environments.
We see maturity progress in stages:
As noted by Computers & Security Journal,
“For the IR process to be effective in dealing with unknown, complex, and sophisticated cyber threats, its underlying activities (detection, containment, eradication, and recovery) must be performed in an agile manner… This requires IR teams to have skills, tools, and processes that enable the enterprise-wide collection, integration, and analysis of all relevant data to make informed decisions in a timely manner.” – Computers & Security Journal
The tools that enable this shift are:
Our role is to help MSSPs integrate these capabilities thoughtfully. Tying them into DevSecOps pipelines and ensuring they work across hybrid cloud and identity systems.
The incident response lifecycle focuses on structured threat handling, while the SOC workflow covers continuous monitoring. A security operations center runs around the clock, reviewing SIEM alerts, triaging events, and escalating risks.
The lifecycle begins when severity increases. It guides tier 1 analysts, tier 2 triage, and IR team coordination through defined steps instead of routine alert handling.
SOC teams reduce alert fatigue by improving the triage process and lowering false positives. Analysts tune SIEM alerts using log correlation, anomaly detection, and behavioral analytics.
Tier 1 analysts filter noise, while cyber threat intelligence adds context. Continuous monitoring combined with better tuning helps detection phase decisions stay accurate and manageable.
A strong containment strategy balances speed with business impact. Teams apply network segmentation, endpoint isolation, and access revocation to stop lateral movement. Incident severity guides the response level.
A clear escalation matrix helps incident commanders act quickly while maintaining coordination and minimizing disruption across hybrid environments.
Post-incident review builds maturity through root cause analysis and clear lessons learned. Teams examine indicators of compromise, timeline reconstruction, and forensic analysis findings.
This process improves SOC metrics such as MTTD and MTTR. Over time, consistent reviews strengthen the maturity model and improve decision-making during future incidents.
Preparation involves structured practice and continuous improvement. Teams run tabletop exercises, red team simulations, and proactive hunting. They map tactics and procedures to MITRE ATT&CK and refine playbook execution.
Strong preparation improves shift handovers, supports clear incident reporting, and ensures teams stay organized during high-pressure ransomware events.
Threats evolve, and your response must evolve faster. A disciplined incident lifecycle transforms noisy alerts into coordinated defense, cutting dwell time and strengthening forensics before damage spreads. Small gaps become costly breaches. Left unchecked.
You have the power to build resilience. Partner with MSSP Security for expert guidance on tool selection and stack optimization, so your SOC matures with clarity and confidence. Act now, lead forward boldly.
