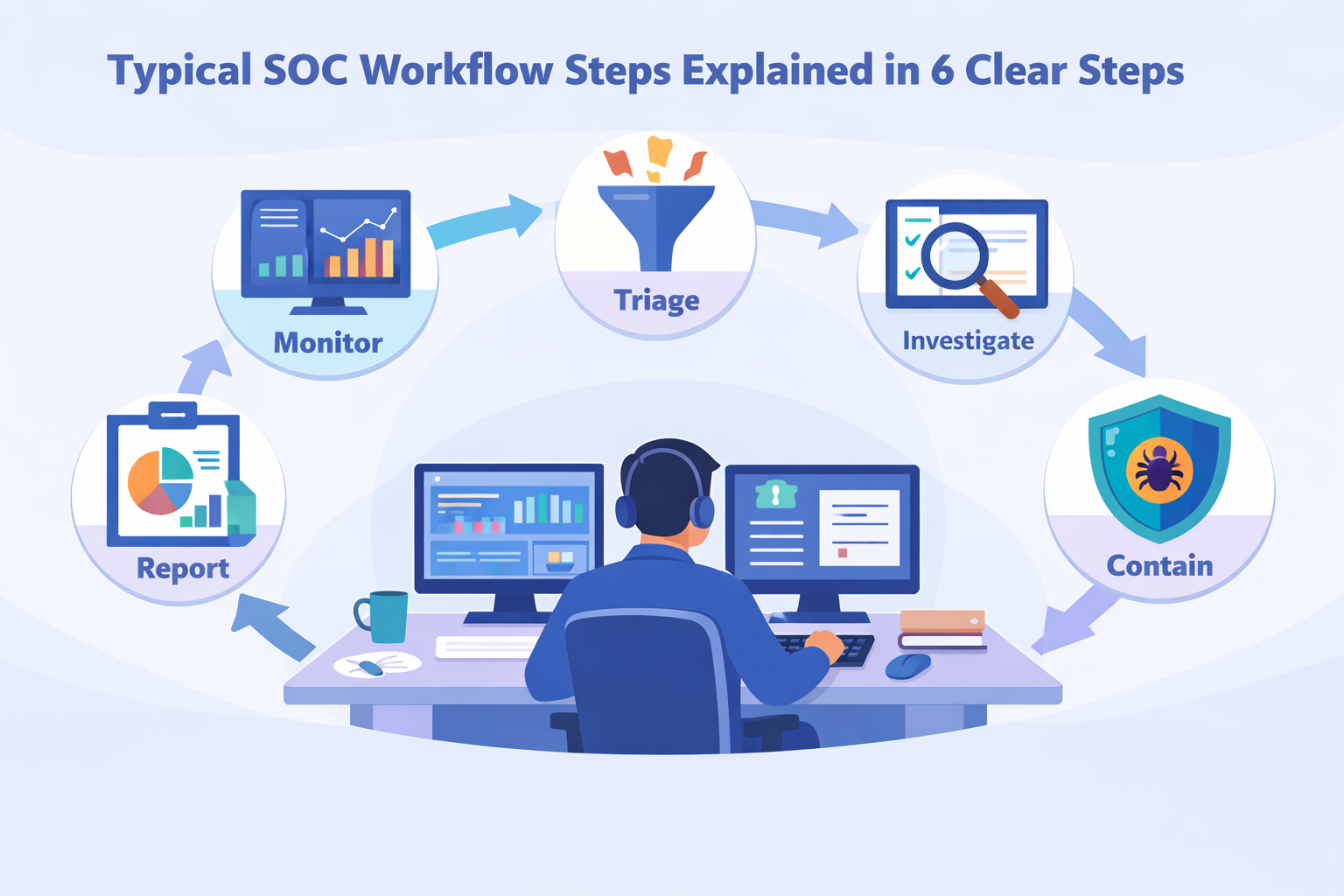
Typical SOC workflow steps explained start with a simple cycle: prepare, monitor, triage, investigate, respond, and improve. Most SOCs follow this loop daily, often mapped to the NIST incident response model. In our work with MSSPs, we’ve seen the difference structure makes.
Teams track three signals: how fast they detect issues, how quickly they acknowledge them, and how long recovery takes. When this rhythm slips, alerts pile up and fatigue grows. When it holds, operations stay calm and decisions stay clear. Keep reading as we walk through how each phase works in real SOC environments.
Quick Wins from Typical SOC Workflow Steps Explained
These points summarize the core lessons behind how real SOC workflows stay consistent and effective.
- The SOC workflow is a continuous loop, not a straight line. It’s built on frameworks like NIST and MITRE ATT&CK.
- Investing time in the preparation phase dramatically cuts down false alarms and makes everyone’s job easier.
- Real improvement is tracked with metrics. MTTD, MTTA, and MTTR tell you if your SOC is getting better or just staying busy.
What are the Core Phases of a SOC Workflow?

A SOC runs on six repeating stages: preparation, monitoring, triage, investigation, response, and improvement. Think of it as a wheel that never stops turning.
It’s modeled after the NIST SP 800-61 guide and uses the MITRE ATT&CK framework to understand attacker behavior. This repeating loop defines a mature security operations center workflow that scales across both internal teams and MSSP environments.
For an MSSP, this structure is non-negotiable. It’s what allows 24/7 coverage, clean handoffs between shifts, and clear rules for when to escalate a problem. Without this loop, your metrics will slip and your team will drown in alerts.
The phases look like this:
- Preparation: Setting up your tools and rules.
- Monitoring & Detection: Watching for anything unusual.
- Triage & Prioritization: Figuring out which alerts matter.
- Investigation: Digging into the “why” and “how.”
- Response & Remediation: Containing and fixing the issue.
- Reporting & Improvement: Learning and getting better.
Every resolved incident should make your detection a little smarter. This is how you build a threat pipeline that actually works, instead of just a collection of noisy tools.
How does The Preparation Phase Cut Down False Positives?
Good preparation stops false positives before they start. It’s about setting clear baselines for normal activity, carefully tuning your SIEM rules, and linking your alerts to specific attacker techniques in MITRE ATT&CK. This work keeps unnecessary noise from hitting your Tier 1 analysts.
Teams pull in logs from endpoints, firewalls, cloud platforms, and identity systems. If this ingestion isn’t structured, your SIEM becomes useless.
We help MSSPs tag their most critical assets and prioritize vulnerabilities using CVSS scores. SANS research shows that mature SOCs have structured preparation; it’s what separates a reactive team from a proactive one.
In practice, the discipline you see inside an MSSP SOC workflow often starts with this groundwork long before alerts ever reach analysts.
Common data sources include:
- Endpoint Detection and Response (EDR) systems
- Network traffic and cloud logs
- Identity and access management alerts
Here’s the difference preparation makes:
| With a Strong Baseline | Without a Baseline |
| Fewer false alarms | Constant alert storms |
| Faster initial triage | Manual log searching |
| Clear sense of urgency | Confused priorities |
| Shorter response times | Delayed escalations |
After we help a client tune their correlation rules, they often see false positives drop by 30% or more. Preparation keeps the whole system from collapsing under its own weight.
What Happens During Monitoring and Detection?

This is the 24/7 watch. Monitoring systems ingest a flood of data, from networks, endpoints, and the cloud, and use rules, behavioral analytics, and threat feeds to generate alerts. Everything flows into a central platform like Splunk, Microsoft Sentinel, or Chronicle.
It’s crucial to understand behavioral detection. Instead of just looking for known bad files (signatures), tools like UEBA spot weird behavior: a user logging in at 3 AM from a new country, or a server suddenly sending out huge amounts of data. IBM’s breach report shows that faster detection saves millions of dollars, which is why a low MTTD is so valuable.
Monitoring looks at:
- Firewall and web proxy logs
- Strange login attempts
- Phishing reports and malware alerts
- Threat intelligence feeds
Automation is a huge help here. AI can gather context for an alert in 30 seconds, a task that might take an analyst 15 minutes. But the human eye is still essential for weird edge cases. Monitoring is where raw data becomes a signal. Everything that follows depends on getting this step right.
How Does Triage Prevent Alert Fatigue?
Triage is the gatekeeper. Its job is to validate an alert’s severity within minutes, filter out the false alarms, and send real threats to the right team. A clear Tier 1, Tier 2, Tier 3 structure is key to preventing burnout.
A Tier 1 analyst validates the alert. They check timestamps, cross-reference logs, and look up indicators in threat feeds. The goal is to decide, escalate or close, in under 5 minutes for critical alerts. The tiered approach works like this:
- Tier 1: Validates and enriches the alert.
- Tier 2: Investigates the scope and impact.
- Tier 3: Handles deep forensics and advanced threats.
We use severity scores (like CVSS) and map everything to MITRE ATT&CK to guide these decisions. Automation platforms (SOAR) can handle repetitive tasks like gathering IP reputations, which saves time. But forums are full of analysts talking about burnout from 12-hour shifts and constant switching between disjointed tools.
Effective triage directly improves your MTTA and MTTR. Managing alert fatigue isn’t about buying another tool; it’s about refining the rules you have, reducing tool sprawl, and having crystal-clear criteria for closing a ticket.
What does a Real SOC Investigation Look Like?
Credits: SANS Institute
When an alert is escalated, the investigation begins. Tier 2 analysts connect the dots. They pull logs from across the environment, firewalls, endpoints, cloud, to reconstruct a timeline and find the root cause. They might use packet captures (PCAP) to spot malicious traffic.
Insights from Softcat indicate
“An incident response is not the hair-raising moment we encounter ransomware, but the routine processes we use to conduct investigations into potential incidents on a daily basis.” – Softcat
A thorough investigation involves:
- Building a forensic timeline of events.
- Preserving evidence properly.
- Mapping the activity to the MITRE ATT&CK framework.
- Using models like the Diamond Model to understand the adversary.
As CISA notes, mapping to MITRE ATT&CK turns abstract alerts into real-world attacker behavior. This tells you if you’re seeing a ransomware deployment or just an admin making a mistake. If the attack is complex, Tier 3 gets involved for deep forensic analysis to find hidden persistence mechanisms.
The investigation answers the critical questions: Was this a real attack? How did they get in? What did they touch? It turns a suspicious blip into a confirmed incident.
How do Response and Remediation Playbooks Work?
When an incident is confirmed, the playbook kicks in. It’s a step-by-step guide for containment, eradication, and recovery. The goal is to limit business impact and restore normal operations as fast as possible. This is where you lower your MTTR.
Containment actions might include isolating an infected endpoint, disabling a compromised user account, or blocking malicious network traffic. Speed is critical to reduce the window of exposure.
A typical response checklist includes:
- Isolate affected systems.
- Reset passwords and enforce MFA.
- Remove malware and backdoors.
- Patch the vulnerability that was exploited.
- Notify internal stakeholders and, if needed, external authorities as per regulations like GDPR.
The NIST framework provides the structure for this. Metrics like Recovery Time Objective (RTO) help prioritize actions. In our work with MSSPs, we integrate SOAR automation to speed up these steps, but we always keep a human in the loop to make judgment calls and preserve evidence. Playbooks ensure a consistent, effective response every time.
How does Reporting Mature The SOC?
The work isn’t done when the ticket is closed. Continuous improvement is what separates a good SOC from a great one. This phase analyzes metrics like MTTD and MTTR, studies false positive rates, and feeds lessons back into the preparation phase.
As noted by Darktrace
“A SOC report… identifies areas for improvement and helps in enhancing the overall security framework.” – Darktrace
After an incident, teams hold a retrospective. What went well? What broke? They update playbooks and run exercises like purple teaming to test their defenses. According to SANS, SOCs mature across 5 levels, from reactive to optimized. Moving up requires this deliberate cycle of review and refinement.
Improvement activities we see in mature MSSPs:
- Tuning SIEM rules based on what they missed.
- Updating incident playbooks with new steps.
- Running attack simulations (tabletop exercises).
- Justifying the SOC budget with clear ROI data.
We treat this as operational hygiene. Daily standups, skill mapping, and cross-training keep analysts engaged and skilled. A SOC never really “finishes.” It either gets better every day, or it slowly falls behind. That ongoing rhythm is best understood by looking at how does a soc operate daily across real-world environments.
What are The Real Pain Points in SOC Workflows?
Talking to SOC analysts every day, we hear the same struggles: burnout from repetitive Tier 1 work, overwhelming “alert storms,” and the mental whiplash of jumping between a dozen different screens.
Online communities describe “SIEM spaghetti”, a tangled mess of overlapping rules. They talk about 12-hour shifts and how MTTR gets worse during messy tool consolidations. Many teams lack the automation to handle simple tasks, or their AI tools are poorly tuned and create more work.
Common pain points include:
- Unmanaged alert fatigue.
- Manual, slow evidence gathering.
- Blind trust in AI without human oversight.
- Sloppy shift handovers.
- Detection rules that don’t match real threats.
New AI and automation tools promise help, and they do reduce workload. But we’ve seen them fail when the underlying process is weak. Misconfigured rules will generate noise no matter how smart the tool is. SOC workflows win when solid process meets the right tools. They fail when technology is expected to replace discipline.
FAQ
How do SOC analyst duties differ across Tier 1, Tier 2, and Tier 3 roles?
SOC analyst duties change based on responsibility level. Tier 1 triage analysts handle SIEM monitoring, review alerts, and filter out false positives. Tier 2 investigation analysts examine the threat detection pipeline, analyze logs, and validate endpoint detection response alerts.
Tier 3 forensics specialists focus on malware eradication tactics, forensic timeline reconstruction, and preserving evidence during serious security incident response cases.
What metrics best measure a cybersecurity operations center’s performance?
A cybersecurity operations center should measure MTTD MTTR metrics, mean time to acknowledge MTTA, and mean time to resolve. These numbers show how quickly teams detect and contain threats. Teams also track KPI dashboard metrics related to alert fatigue management and incident closure criteria. Measuring both speed and accuracy helps leaders understand true operational performance.
How can teams reduce alert fatigue without missing real threats?
Teams reduce alert fatigue by improving SIEM correlation rules and refining anomaly detection rules based on real attack data. They use threat intelligence feeds and behavioral analytics engines, including UEBA user entity behavior insights, to filter noise. Clear escalation matrix criteria and well-defined playbook standardization prevent analysts from wasting time on low-risk alerts.
What makes a strong incident handling playbook effective?
A strong incident handling playbook follows the NIST incident response framework and outlines clear ransomware containment steps, stakeholder notification protocol, and root cause analysis RCA procedures. It defines incident closure criteria and supports post-incident review discussions. Over time, teams document lessons in a lessons learned database to improve future response consistency.
How do mature SOC teams improve their workflow over time?
Mature SOC teams rely on a continuous improvement loop supported by weekly retrospective meetings and annual tabletop exercises. They update detection engineering best practices and refine MITRE ATT&CK mapping as threats evolve. Skills matrix mapping, cross-training rotations, and burnout prevention strategies help teams stay capable while adapting to new security challenges
Why Typical SOC Workflow Steps Still Win in Practice
A SOC is not a scramble, it is a cycle. When preparation, monitoring, triage, investigation, response, and improvement align with the National Institute of Standards and Technology frameworks and the MITRE Corporation ATT and CK, chaos fades and clarity rises. How long can you afford drift before strain becomes risk?
Build a SOC that protects without burning out your team, explore expert SOC consulting today and lead confidently.
References
- https://www.softcat.com/blog/five-steps-build-your-security-operations-centre-soc
- https://www.darktrace.com/cyber-ai-glossary/soc-operations-and-processes-triaging-soc-alerts-soc-reporting-soc-kpis