
How does a SOC operate daily? A Security Operations Center runs as a 24/7 hub that monitors alerts, investigates threats, and responds fast to reduce risk and response time. In many mid-sized environments, teams sift through thousands of daily events and surface real threats within minutes.
Good operations tie monitoring, detection, and response into one steady loop. From what we see at MSSP Security, the pace feels constant but disciplined. Analysts follow clear playbooks, measure outcomes, and stop small signals from turning into public incidents. Keep reading to see what really happens behind the dashboards.
Daily SOC Operations at a Glance
A quick summary of how a SOC operates daily, from monitoring loops to proactive defense maturity.
- A SOC operates 24/7 using a structured cycle: monitor, triage, investigate, respond, and report to reduce risk and maintain operational continuity.
- Tiered analysts, automation playbooks, and continuous detection rule tuning help lower false positives and improve MTTR.
- Mature SOCs move beyond reactive alerts by investing in proactive threat hunting, behavioral analytics, and measurable performance metrics.
What Does a SOC Do Every Day?
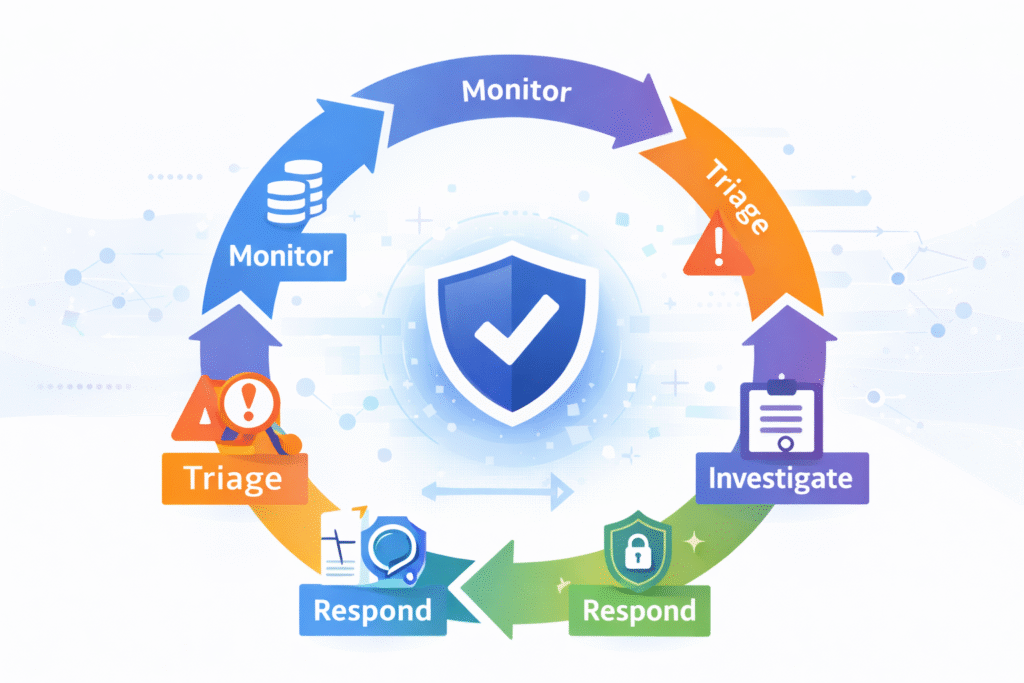
A Security Operations Center never really sleeps. On any given day, a team might look at over ten thousand events. If you’re wondering what a SOC does, the answer comes down to disciplined repetition backed by clear process.
In our work with MSSPs, we see how these teams start their day. It usually begins with a shift change. The incoming analysts get briefed on any ongoing investigations, check their response time goals, and review live dashboards. The monitoring cycle is constant.
Most centers organize their work around a common framework with five parts: Identify, Protect, Detect, Respond, and Recover. It’s a helpful structure. But a big problem many teams face is false alarms.
The daily grind follows a pretty consistent loop, no matter the industry:
- Monitor: Collecting logs and watching for alerts.
- Triage: Sorting alerts to find the real problems.
- Investigate: Digging into what happened.
- Respond: Containing the threat and fixing things.
- Report: Documenting the incident and tracking performance.
It’s less like a spy movie and more like a very disciplined, repetitive process. Thousands of alerts flow through these steps. Success comes from good tools, sure, but it depends more on a well-tuned process and a team that communicates clearly.
Who Does What On The Team?
Most SOC teams run on a three-tier model. It keeps the noise manageable and gives people room to specialize. If you look at an MSSP SOC workflow, you’ll notice the same tiered structure repeated across different environments.
Tier 1 sits at the front line. They review the flood of alerts, close the obvious false positives, and escalate anything that feels off. Tier 2 picks it up from there. These analysts dig deeper, trace root cause, and begin containment. Tier 3 focuses on the hard stuff, threat hunting, complex malware, and improving detection logic over time.
In real environments we audit, speed matters. Strong teams move a real incident from Tier 1 to Tier 2 in about 15–30 minutes. In a mid-sized operation, ten thousand daily events isn’t unusual. Without clear tiers, the backlog grows fast.
Here’s a simple snapshot:
| Tier | Main Job | Common Tools | What They Measure |
| Tier 1 | Alert triage, false-positive filter | SIEM dashboards, ticketing systems | Alert closure speed |
| Tier 2 | Deep investigation, containment | EDR tools, forensic platforms | Time to contain threats |
| Tier 3 | Proactive hunting, research | Threat intel platforms, custom queries | New threats discovered |
We often see friction in handoffs. When escalation paths are messy, risk creeps up. Clean tier boundaries keep analysts focused and the whole system steady.
How Do They Spot Threats In Real Time?

The SOC brings all its data into one central system, logs from firewalls, network traffic, user activity, and more. It correlates this information to spot unusual behavior as it happens, which is core to any mature security operations center workflow.
Why is speed so important? Studies show that the longer an attacker goes undetected, the more damage they can do. The first hour after a breach is critical.
Monitoring isn’t passive. It uses several key sources:
- Behavioral Analytics: Spotting when a user or device acts out of the ordinary.
- Threat Feeds: Checking activity against known indicators of attack.
- Risk Scoring: Automatically ranking alerts by how serious they seem.
As noted by SANS Institute
“The daily operation involves continuous monitoring of events… Analysts utilize behavioral analysis and threat intelligence to distinguish between normal background noise and a legitimate security incident.” – SANS Institute
Here’s a typical example: At 2 AM, the system flags a server sending a huge amount of data out. The behavioral profile for that server looks nothing like its normal pattern. A Tier 1 analyst checks it, sees it’s also running a weird process, and escalates it to Tier 2. Good detection mixes machine speed with human judgment.
What’s It Like To Triage Alerts All Day?
Alert triage is about fast judgment, repeated all shift. Analysts review an alert, weigh the system involved, check credibility, and choose a path: close it, dig deeper, or escalate. The rhythm is quick and steady.
Across the SOCs we assess, mature teams try to handle high-risk alerts in under 30 minutes. Most use simple scoring models to stay consistent. They look at a few signals:
- Business value of the affected asset
- Confidence in threat intelligence
- How abnormal the behavior appears
Consider a phishing alert. A Tier 1 analyst reviews the sender, tests the link against intel feeds, and scans the user’s recent activity. If risk holds up, containment starts right away, blocking the URL, flagging the domain, sometimes isolating the endpoint. We’ve seen stronger MSSPs standardize these steps with playbooks, especially after tooling audits.
Each false positive still pays off. When teams label noise correctly, they tune rules, refine filters, and adjust detection logic. Over time, that feedback loop cuts alert volume and sharpens response. The best environments treat triage as both defense and continuous tuning.
What Happens When They Find A Real Attack?
When a real attack is confirmed, response shifts into motion fast. Teams lean on pre-built playbooks to contain the threat and limit spread. The difference shows in preparation. SOCs that rehearse these moments tend to shorten downtime and reduce overall impact.
Most responses follow a familiar pattern. The order may vary, but the core steps stay steady:
- Isolate affected devices from the network
- Block malicious IPs or domains at the edge
- Remove malware and persistence mechanisms
- Restore systems from clean, verified backups
- Run a post-incident review to capture lessons
Insights from CISA indicate
“Upon detection of a high-priority event, the SOC initiates an incident response workflow to contain the impact, which may include isolating affected systems, disabling compromised accounts, and blocking malicious IP addresses at the firewall.” – CISA
In the environments we audit, tooling helps but doesn’t carry the response alone. Automation can quarantine hosts or push blocks quickly, yet coordination still decides the outcome. We often see MSSPs succeed when roles are clear and playbooks match real workflows, not theory.
Communication becomes the anchor once pressure rises. Clients want clarity, not noise. The strongest teams keep updates simple, frequent, and honest while they work the problem. Good incident response blends technical control with calm execution and tight alignment across everyone involved.
How Do They Know If They’re Doing A Good Job?
Credits: TechTual Chatter
So how do SOC teams know they’re doing well? They measure almost everything. Daily reports log incident counts, resolution time, alert quality, and workload trends. Over time, those numbers paint a clear picture of team health and where friction hides.
Across the MSSPs we work with, a few metrics show up in every dashboard. They’re simple, but they drive real decisions:
- Mean Time to Respond (MTTR): How quickly threats are contained
- False Positive Rate: How noisy detection rules are
- Escalation Rate: How accurate early triage tends to be
We often review these metrics during tooling audits. When numbers drift, it’s usually a signal that detections, processes, or even products need tuning. Small changes can move the needle more than people expect.
Progress rarely comes from one big fix. Teams refine rules, run tabletop exercises, and tighten training loops week by week. We’ve seen MSSPs cut alert noise meaningfully just by cleaning up detection logic after a review. Less noise lowers fatigue and frees analysts to focus on real threats. The best SOCs let yesterday’s data shape tomorrow’s playbooks.
Why Do Analysts Get Burned Out?
Burnout shows up fast in SOC work, and alert fatigue is usually the root. Analysts face thousands of alerts per shift, many of them harmless. In less mature setups we review, noise can dominate the queue. Add long shifts and constant pressure, and exhaustion builds quickly.
The talent gap makes it worse. Many teams run lean, so the same analysts carry heavy loads week after week. From what we see during MSSP audits, burnout rarely comes from one cause. It’s usually a mix of structural issues:
- Alert storms from poorly tuned detections
- Rotating shifts that disrupt sleep cycles
- “Smart” tools that still demand manual triage
- Limited growth paths for Tier 1 analysts
We’ve sat in reviews where teams tried to solve fatigue by swapping tools alone. That rarely works. Burnout tends to track process maturity more than product choice.
Relief usually starts with cleaner operations. Tightening alert rules, standardizing playbooks, and investing in proactive hunting all help. When MSSPs reduce noise and clarify workflows, analysts regain focus. Treating fatigue isn’t optional, it’s part of running a stable SOC.
How Are SOCs Changing?

SOC work is shifting from reactive to proactive. Strong teams don’t just wait for alerts anymore. They hunt for threats that slip past automation and look for patterns that tools might miss. The goal is simple: find attackers earlier and shrink dwell time inside the network.
Across the MSSPs we advise, this shift often starts with structure. Teams lean on attacker-behavior frameworks and real telemetry to guide hunts. Instead of chasing noise, they test focused ideas and refine from there. Common patterns include:
- Forming hunt hypotheses based on recent attack trends
- Tuning baselines to better define normal behavior
- Building light automation for repeat tasks
- Tracking active threat groups and evolving tactics
We usually see this evolve after tooling reviews. Once detections stabilize, teams gain room to hunt. The results can be subtle but meaningful.
In several engagements, proactive hunting surfaced weak signals early, odd logins, quiet lateral movement, small anomalies that never fired major alerts. Catching those moments changes outcomes. With the right process and tuned tools, MSSPs move from reacting to incidents toward quietly preventing them.
FAQ
How does SOC shift handover work in 24/7 operations staffing?
SOC shift handover keeps coverage smooth across 24/7 operations staffing. Teams share handover briefing notes, update the ticketing system workflow, and review real-time dashboards together.
They summarize open alerts, note response time SLA risks, and confirm containment checklist progress. Clear SOC team collaboration tools help prevent gaps, so the next shift continues the continuous monitoring cycle with full context.
What happens during tier 1 analyst triage and false positive filtering?
Tier 1 analyst triage focuses on fast, clear decisions. Analysts review SIEM alert monitoring, apply false positive filtering, and use a prioritization matrix to rank risk. They check threat intelligence feed context, validate anomaly detection rules, and review behavioral analytics alerts. When risk looks real, they trigger the incident escalation protocol so higher tiers can investigate quickly.
How do teams run a threat hunting workflow daily?
A daily threat hunting workflow starts with proactive hunting queries and UEBA user entity behavior insights. Analysts review the log aggregation pipeline, test anomaly detection rules, and watch for APT campaign patterns. They compare proxy traffic analysis, firewall log review, and network flow monitoring to spot subtle anomalies. Results often lead to detection rule tuning or simulated attack testing.
What is included in incident escalation and tier 2 forensics investigation?
Once escalation begins, teams follow a clear incident escalation protocol. Tier 2 forensics investigation includes forensics timeline reconstruction, root cause analysis, and EDR endpoint detection checks.
Analysts use XDR correlation analysis to confirm scope, verify containment checklist steps, and guide recovery playbook execution. This structured approach helps protect response time SLA and keeps decisions consistent.
How do SOCs measure performance and prevent alert fatigue?
SOCs track performance through a metrics KPI dashboard and daily incident reporting. Teams monitor alert fatigue mitigation trends, response time SLA targets, and post-incident review findings. Many align progress with a SOC maturity model and capture lessons learned documentation.
Regular detection rule tuning, training drill simulation, and runbook standardization improve outcomes while reducing long-term analyst strain.
What Daily SOC Operations Reveal About Maturity
A SOC reveals its maturity in calm moments, when monitoring is disciplined, investigations are precise, and containment is swift. Metrics guide action, intelligence sharpens vision, and teams move from reacting to anticipating. The real risk is not the loud breach, it is the quiet drift into complacency that drains trust and confidence.
With MSSP Security, shift from firefighting to foresight. Strengthen detection, empower your team, and build resilience every day. Act now, because proactive defense is earned, not assumed.
References
- https://www.sans.org/white-papers/36602/
- https://www.cisa.gov/news-events/news/soc-operations-best-practices