Determining incident root cause is the difference between fixing noise and fixing reality. Too many teams patch symptoms, then watch the same problem return. According to incident management research, strong Root Cause Analysis (RCA) prevents recurrence by targeting underlying failures.
We have seen this firsthand. Keep reading to learn a practical, no-blame approach that actually works in real environments.
What Matters Most
- Root Cause Analysis focuses on systems, not individual blame.
- Simple tools like the 5 Whys often reveal deep systemic failures.
- Corrective actions must be verified or incidents will return.
Start With a Clear Incident Definition
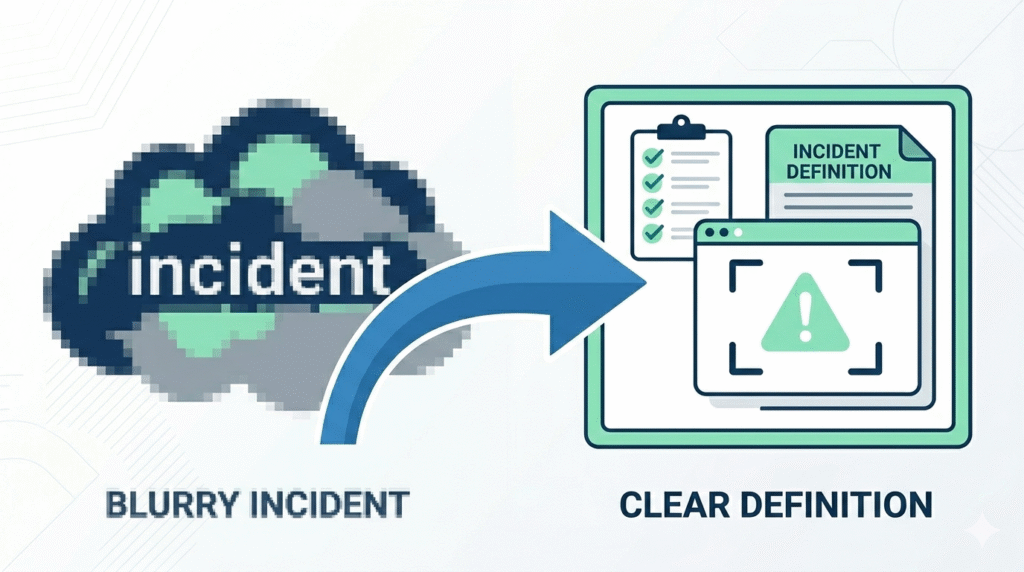
Every strong incident investigation begins with clarity. Teams often rush ahead with guesses. That is where root causes hide.
“AI-powered technology doesn’t replace human analysis, it augments the analyst’s expertise by quickly piecing together an attack narrative from disparate sources and rapidly identifying crucial connections that could take days to discover manually.” – Darktrace
A useful incident report should answer five basics:
- What happened
- When it happened
- Where it occurred
- Who was involved
- What the sequence looked like
For example, “Server overloaded during peak traffic at 3:15 PM” beats vague language every time. In our MSSP Security work, we treat this security incident investigation process as non-negotiable. Without precision, later analysis becomes opinion, not evidence.
This is also where observability platforms and monitoring tools shine. Clean logs, timeline data, and performance metrics make the investigation progress faster and more defensible.
Gather Evidence Before Forming Theories
Strong root-cause analysis is evidence-first. Opinions come later.
Teams should collect:
- System logs
- Witness notes
- Environmental conditions
- Sequence diagrams
- Change tracking data
Many failures blamed on human errors later trace back to organizational issues or broken business processes. We have seen teams blame an operator when the real problem was flawed Standard operating procedures.
Data Analytics helps here. When teams use trend analysis and Process Behavior Chart reviews, patterns emerge quickly. This step also protects the site owner during audits by showing disciplined investigation management workflows.
The rule is simple: if it is not documented, it did not happen.
Separate Immediate Causes From Root Causes
Credits: Safety+Health Youtube Channel
This is where many teams fail.
An equipment malfunction or oil leak is rarely the true root cause. Those are triggers. The deeper causes and effects usually live in the system.
Common immediate causes include:
- Equipment failures
- Malformed data from an SQL command
- Online attacks
- Environmental conditions
- Safety incidents
But deeper systemic challenges often involve weak change management, poor employee engagement, or gaps in supply chain processes. MSSP Security teams focus heavily on this layer because it is where long-term risk lives.
Use Proven Root Cause Analysis Techniques

Not every incident needs the same tool. Smart teams pick methods that match complexity.
Most effective RCA tools:
- 5 Whys Technique (fast and simple)
- fishbone diagrams or Ishikawa diagram (visual brainstorming)
- Pareto analysis using a Pareto chart (prioritization)
- Failure Mode and Effects Analysis for high-risk systems
- Causal Factor Analysis and logic or event trees for complex failures
- Scatter Diagrams for correlation checks
- change analysis for configuration drift
The Five whys method works well for many operational issues. But for Pharmaceutical Manufacturing or Medical Device environments, more formal Root Cause Analysis System approaches are often required.
We often combine methods, following comprehensive steps to analyze a security incident, as one tool rarely tells the full story.
Reddit’s Anti-Blame Reality Check
Blame culture kills learning. When teams fear punishment, incident investigation becomes theater. Real preventive actions never happen. In MSSP Security engagements, we assume good intent first. Then we examine security processes, change management, and systemic challenges that made the failure possible.
This approach improves customer experience and speeds Postmortem call discussions. It also aligns with modern safety audits and Quality Management System expectations. Systems fail. People operate inside systems.
Match Corrective Actions To Risk Impact
Finding root causes means nothing without corrective measures.
“MSSPs help companies establish security improvements by revealing the actual cause enabling organizations to stop future incidents. Such an approach to security gives organizations better protection across all their cybersecurity systems.” – ITButler
Effective corrective actions should be:
- Specific
- Testable
- Assigned to owners
- Time-bound
- Verified through safety metrics
High-risk environments like Process Safety Management programs or Risk Management Program compliance require documented follow-through. Agencies such as the Occupational Safety and Health Administration and the U.S. Environmental Protection Agency expect proof, not promises.
We recommend tracking:
- corrective actions
- preventive actions
- safety measures
- Overall Equipment Effectiveness
- cost of risk and Total Cost of Risk
Without this discipline, Product Recalls, catastrophic releases, and recurring operational issues become far more likely.
Example RCA Flow in Modern Operations
| Step | What Teams Do | Tools Often Used | Outcome |
| Define incident | Build precise incident report | Monitoring tools, observability platforms | Clear scope |
| Gather data | Collect logs and timelines | Data Analytics, sequence diagrams | Evidence base |
| Find causes | Map causes and effects | 5 Whys, fishbone diagrams | Root causes |
| Fix issues | Apply corrective actions | QHSE software, workflow tools | Risk reduced |
| Verify | Track performance metrics | Process Behavior Chart | Recurrence prevented |
This structured flow works across security service environments, manufacturing, and safety programs.
Where Many Root Cause Efforts Break Down
Even experienced teams struggle. We see the same patterns repeatedly.
Common RCA failure points:
- Stopping at human errors
- Skipping Gemba Gembutsu (going to the real place)
- Weak change tracking
- No follow-through on preventive actions
- Poor cross-team employee engagement
- Treating RCA as paperwork
Tool overload can also hurt. Platforms like TrackWise Digital or New Relic provide powerful data, but without disciplined thinking, even the best Root Cause Analysis System becomes noise.
The ADKAR Model reminds us that organizational change must be managed deliberately. Otherwise, fixes fade and incidents quietly return.
Building RCA Into Everyday Operations
The strongest teams do not treat root-cause analysis as a one-off exercise. They embed it into daily incident management workflows.
In mature environments, we see:
- Routine Postmortem call culture
- Continuous safety audits
- Integrated Quality Management System reviews
- Regular Process Safety Management checks
- Mechanical integrity program validation
- Relief valve system inspections
This is where observability platforms and security solution telemetry create real value. When signals flow cleanly, incident investigation analysis steps accelerate and systemic risks surface much earlier.MSSP Security encourages this continuous model because it reduces long-term operational drag while improving safety metrics and customer feedback trends.
FAQ
How do teams avoid blaming people during Root Cause Analysis?
Strong Root Cause Analysis looks past human errors and focuses on systems. Teams review business processes, environmental conditions, and organizational issues before assigning fault. Using tools like the 5 Whys Technique and Event Analysis helps expose deeper causes and effects.
This approach improves employee engagement, supports healthier incident management workflows, and keeps investigation progress focused on prevention instead of blame.
When should you use fishbone diagrams instead of the 5 Whys?
Fishbone diagrams work best when incidents involve many possible causes across business processes or environmental conditions. The Ishikawa diagram, created by Kaoru Ishikawa, visually groups causes and effects, which helps teams see patterns quickly.
The Five whys method is better for simple chains. Complex safety incidents or equipment failures usually benefit from the broader structure of fishbone diagrams.
What role does Data Analytics play in finding root causes?
Data Analytics strengthens root-cause analysis by revealing hidden patterns in performance metrics and trend analysis. Teams often combine Scatter Diagrams, Process Behavior Chart reviews, and Pareto analysis to validate assumptions.
Observability platforms and Monitoring tools also help. When data supports findings, corrective actions become more precise, improving customer experience and reducing the Total Cost of Risk over time.
How do preventive actions differ from corrective measures after incidents?
Corrective measures fix what already failed, such as equipment malfunction or broken Standard operating procedures. Preventive actions go further by addressing systemic challenges and organizational change risks before recurrence. Mature programs track both through safety metrics and Change tracking.
This balanced approach strengthens Quality Management System maturity and supports long-term stability across supply chain processes and operational issues.
The Bottom Line
Determining incident root cause requires discipline, evidence, and a system-first mindset. Teams that go beyond surface fixes prevent repeat failures, reduce risk, and improve long-term performance.
The key is consistent Root Cause Analysis backed by verified corrective actions. If your team needs expert guidance to strengthen operations and visibility, explore MSSP Security support and take the next step toward more resilient incident management.
References
- https://www.darktrace.com/cyber-ai-glossary/root-cause-analysis
- https://itbutler.sa/blog/how-mssps-support-incident-management-and-recovery-processes/